
On KernelBench’s hardest Level‑3 tasks, the authors claim CUDA Agent beats torch.compile’s speed in ~92% of cases and outperforms Claude Opus 4.5 and Gemini 3 Pro by about 40 percentage points on the “faster than compile” rate.
That’s not “LLM writes cute CUDA snippets.” That’s “an RL agent, with hardware in the loop, consistently out‑optimizes both compiler heuristics and frontier general models on real kernels.”
The argument here is simple: CUDA Agent is not yet something you should trust in production. But it is the benchmark‑shaped warning shot you and your infra team should try to reproduce now, because if these numbers hold up, the right way to optimize kernels in two years won’t be “tune flags” or “prompt Opus”, it’ll be “spin up a specialist RL agent.”
Why CUDA Agent Matters Now
Let’s ground it in one scenario.
You have a hot fused op that eats 20% of your training step time. Today your options look like:
- Flip more
torch.compileknobs and pray Inductor finds a better schedule - Bribe your friend who “actually likes CUDA” to hand‑tune it
- Throw Claude Opus or Gemini a prompt and sift through semi‑correct kernels
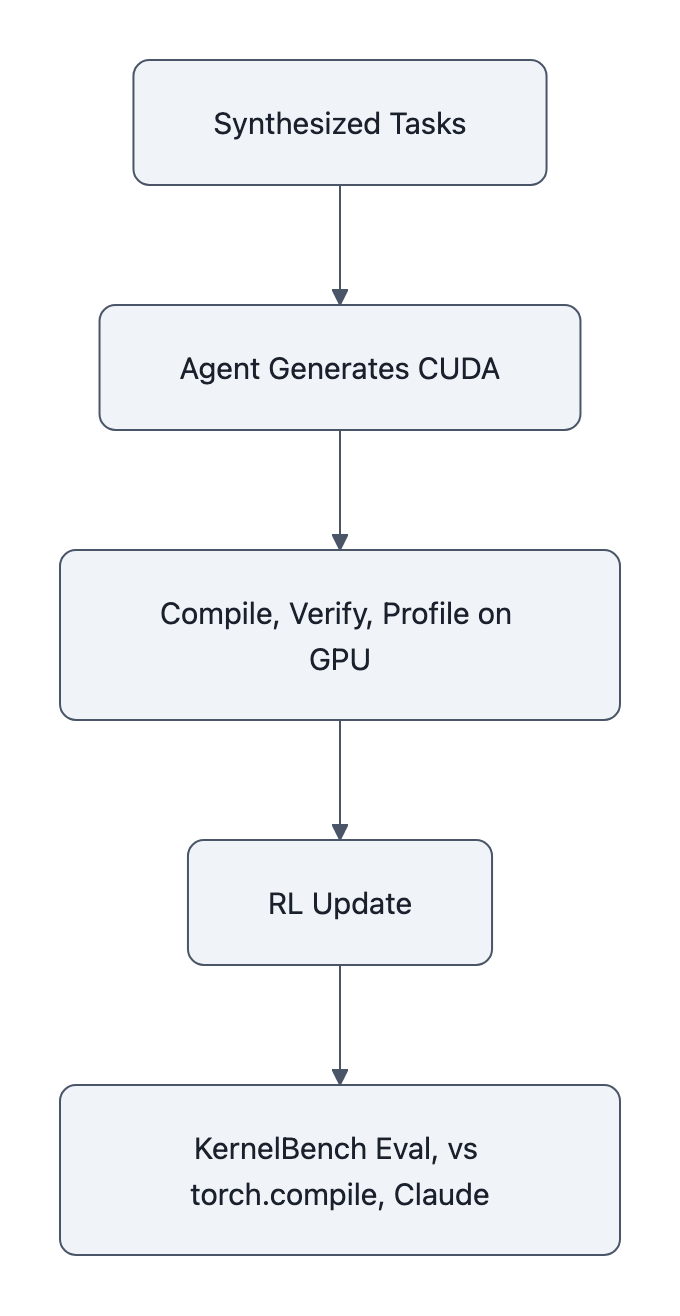
CUDA Agent proposes a fourth path: an agentic RL loop that lives inside a CUDA dev environment, generates kernels, compiles them, runs them on a real GPU, checks correctness, profiles speed, and then updates a policy model to do better next time.
The key difference from compilers and one‑shot LLMs is that the agent:
- Owns the loop, it can write scaffolding code, tweak launch params, retry variations
- Sees real rewards, wall‑clock GPU time, not just “does it compile”
- Trains on synthesized, execution‑filtered tasks built from real PyTorch operators
In other words, compilers expose a fixed optimization brain; general LLMs bring a big but clueless brain; CUDA Agent is a specialist brain that learned on the machine itself.
That’s why this isn’t just another benchmark flex. It’s a blueprint for how we’ll optimize everything performance‑critical if it works.
CUDA Agent’s Benchmark Results and How They Were Measured
The authors evaluate CUDA Agent on KernelBench, a curated set of CUDA kernel tasks with three difficulty levels.
Their headline numbers:
- 98.8% overall pass rate (i.e., kernels produce correct outputs on test inputs)
- 96.8% “faster‑than‑torch.compile” rate overall
- 2.11× overall geometric‑mean speedup vs torch.compile
On the level splits, they report:
- Level‑1: 100% of kernels faster than torch.compile
- Level‑2: 100% faster
- Level‑3 (hardest): 92% faster
For proprietary models, the paper says strong general LLMs (Claude Opus 4.5 and Gemini 3 Pro) hit only ~66-70% faster‑than‑compile rates and ~1.42-1.46× speedups, versus CUDA Agent’s 96.8% and 2.11×.
So how do they get these numbers?
Roughly:
- Data synthesis
- Crawl seed ops from torch/transformers
- Compose up to five ops into fused tasks via an LLM
- Filter tasks via execution: they must run under eager and compile, be deterministic, and have 1-100ms eager runtime
- Remove near‑duplicates and KernelBench lookalikes
- Result: CUDA-Agent-Ops-6K, a 6,000‑sample dataset released on Hugging Face
- Agentic RL loop
- Policy proposes kernels + helper code in a long‑context environment
- System compiles, runs, verifies correctness, profiles GPU time
- Reward combines pass/fail and speed vs a torch.compile baseline
- RL algorithms are tuned for long‑horizon, long‑context sequences
- Evaluation
- Run agent‑generated kernels and baselines (torch.compile, proprietary LLMs) on KernelBench
- Measure pass rate and relative speed
- Aggregate into faster‑than‑compile rates and speedup factors
So the CUDA Agent story is not “LLM learned CUDA from GitHub.” It’s “RL trained on 6,000 execution‑filtered tasks, with the GPU as the reward oracle.”
And that’s a big conceptual shift: instead of optimizing code by hand, you’re optimizing a code generator with the hardware in the loop.
Why The Claims Need Independent Reproducibility
If you’ve read Are Large Language Models Reliable for Business Use?, you already know the pattern: glossy headline numbers, messy reality once you leave the lab.
CUDA Agent has all the right reproducibility signals on paper:
- Code on GitHub, including the agent workdir
- Dataset on Hugging Face (CUDA-Agent-Ops-6K)
- Clear benchmark (KernelBench) and baselines (torch.compile, named models)
But these are still author‑reported experiments. No independent lab has yet re‑run the whole thing and confirmed “yep, 2.11× on our machines too.”
For something this consequential, that gap matters:
- Hardware sensitivity
- Kernel performance is brutally tied to GPU model, SM count, memory hierarchy, driver, CUDA/cuDNN versions
- An agent overfitted to, say, an A100 with a particular driver stack might not look so magical on an H200 or a consumer RTX
- Benchmark coupling
- They say they filtered to avoid KernelBench contamination, but the whole dataset is synthesized from the same torch/transformers ops world
- Subtle leakage or shape biases could make KernelBench a friendly test for this particular agent, inflating perceived generality
- Reward hacking and edge cases
- They explicitly run anti‑hacking checks (e.g., removing constant‑output solutions), but any RL system with execution rewards is always flirting with weird edge behaviors
- A 98.8% pass rate still leaves 1.2% of kernels that are wrong, in production, one such kernel in a critical path is a postmortem
We’ve written about Model Collapse: Can AI Eat Itself?, how models feed on their own outputs and drift. CUDA Agent is a different version of that risk: your infra might start to trust an opaque optimization brain trained on a narrow diet of synthetic tasks.
If you’re going to deploy something like this, you don’t accept “trust me bro + arXiv plots.” You run your own silicon‑level due diligence.
What Developers and Teams Should Do Next
So what do you do with CUDA Agent today?
Treat it as a priority test case, not a turnkey tool.
You don’t need to reproduce the entire paper to get value. You need a tight experiment that answers one question for your stack:
“On our hardware, for our style of ops, does this agentic RL loop actually beat torch.compile and AI-generated CUDA code by enough to matter?”
Here’s a low‑friction plan.
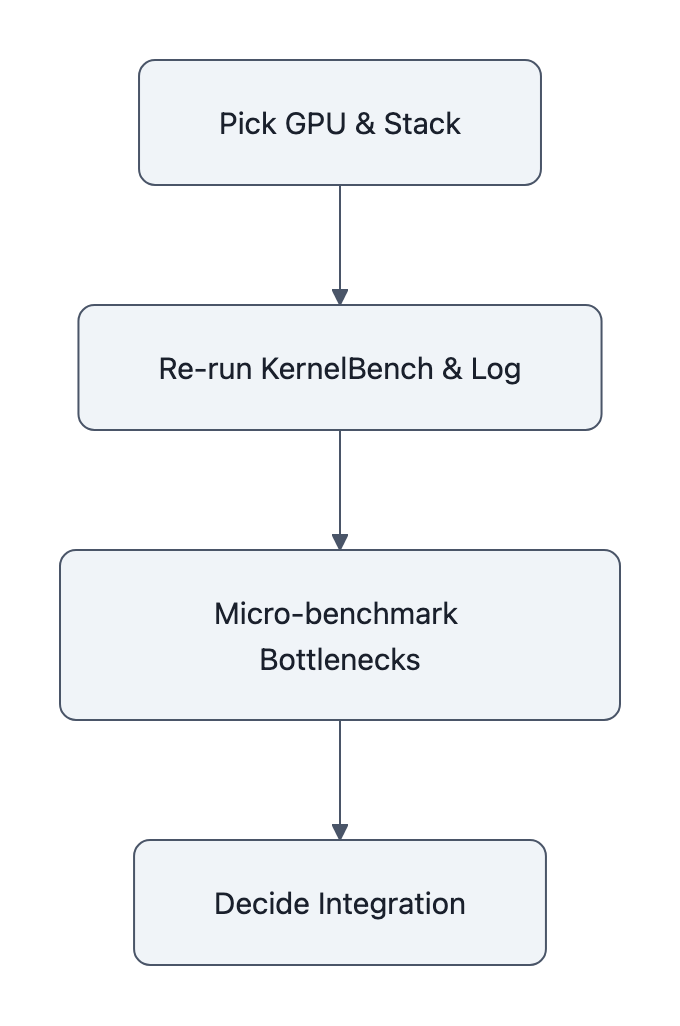
1. Pick a single GPU + stack and lock it
Choose a configuration you care about and freeze it:
- GPU: e.g., A100‑80GB, H100, or your most common inference card
- Driver + CUDA version
- PyTorch version and
torch.compilesettings you consider “best effort”
Document this once. All comparisons, CUDA Agent vs torch.compile vs proprietary LLMs, must use this exact stack.
2. Re‑run their KernelBench eval, but log everything
Pull from:
Then:
- Run the provided evaluation scripts on KernelBench
- Record per‑kernel:
- correctness (pass/fail)
- absolute runtime (not just speedup factor)
- any compile failures or fallbacks
- Sanity‑check a random sample of outputs manually, especially failures and “weirdly huge” speedups
You’re not trying to hit 98.8% on the nose. You’re looking for shape:
Is it still consistently faster than torch.compile? Or does the magic evaporate once it leaves the authors’ devbox?
3. Add your own micro‑benchmark
KernelBench is good, but you care about your ops.
Pick one or two real bottlenecks:
- A fused attention block
- A custom normalization or loss function
- A gnarly data‑prep kernel that hits PCIe or shared memory hard
Run three baselines:
torch.compilebest effort- Your best hand‑tuned CUDA / Triton (if you have it)
- A prompt‑engineered Claude Opus 4.5 / Gemini kernel, sanity‑checked for correctness
Then run CUDA Agent on the same tasks and compare.
This gives you the number that actually matters to the business: “We can shave X% off end‑to‑end iteration time if we bolt this agent into our pipeline.”
4. Decide how far to integrate the CUDA Agent loop
If the numbers look good, don’t jump straight to “let’s refactor everything to RL agents.”
Start by wrapping CUDA Agent as an offline suggestion engine:
- Feed it candidate ops or small fused graphs
- Have it produce kernels that go through your existing CI + benchmarking harness
- Only promote those that pass correctness, regression tests, and offer a material speedup
In other words: treat CUDA Agent as a super‑powered contractor, not as the chief architect of your GPU stack.
If it keeps delivering, then you can talk about deeper integration, e.g., plugging an agentic loop into your compiler pipeline or build system.
The meta‑point: CUDA Agent is the first convincing glimpse of a world where optimization is no longer a compiler pass or a one‑shot model call, but an ongoing conversation between an agent and your hardware.
That’s too important to ignore, and too early to blindly trust.
Key Takeaways
- CUDA Agent uses hardware‑in‑the‑loop, agentic RL on synthesized, execution‑filtered tasks to train a CUDA specialist that beats torch.compile and strong LLMs on KernelBench.
- The authors report 98.8% pass rate, 96.8% faster‑than‑compile rate, and 2.11× speedup vs torch.compile, plus a ~40‑point edge over Claude Opus 4.5 and Gemini 3 Pro on the hardest tasks.
- These are author‑reported, hardware‑sensitive numbers; independent reproducibility on diverse GPUs and workloads is the real test before production use.
- Teams should treat CUDA Agent as an urgent experiment, not a drop‑in replacement: re‑run KernelBench on your stack, test it on one or two real bottlenecks, and only integrate via guarded, offline optimization loops.
- If this pattern holds, specialist RL agents like CUDA Agent could quietly become the default route for kernel‑level optimization across Nvidia’s hardware and software stack.
Further Reading
- CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation (arXiv), Full paper with KernelBench results, RL details, and comparisons to torch.compile and proprietary models.
- CUDA Agent, project site, Overview, key metrics (98.8% pass rate, 2.11× speedup vs torch.compile), and links to code and data.
- CUDA-Agent repository (GitHub), Implementation of the CUDA Agent workflow and scripts for running evaluations.
- CUDA-Agent-Ops-6K (Hugging Face dataset), The synthesized 6,000‑sample training set used for agentic RL.
- ByteDance Trained an AI Agent That Writes Faster CUDA Kernels Than You (AwesomeAgents), Third‑party summary of CUDA Agent’s design and claimed impact.
The next year of CUDA won’t be decided by who has the cleverest hand‑written kernel; it’ll be decided by who figures out how to industrialize this kind of agentic loop, or proves it doesn’t generalize. Either way, you don’t want to be watching from the sidelines.