
Six hours into a “set-and-forget” agent run, your dashboard lights up yellow. The chain is still going, GPU bill creeping upward, 700,000 tokens into a 1 million token context window, and you realize the root prompt had the wrong customer ID format.
Welcome to the GPT-5.4 era, where the bug isn’t just a bad response, it’s a four‑hour burn of compute and a half‑gigabyte of context you now have to reason about.
According to The Information, GPT-5.4 will add two big knobs: a 1M‑token context window and an “extreme reasoning mode” that can run for hours on hard problems, with OpenAI moving toward monthly model updates instead of big splashy releases. The argument here is simple: GPT-5.4 is the moment you stop treating “model choice” as a dropdown and start treating compute, runtime, and state as core product decisions.
If you don’t, your “AI feature” is about to become an uninstrumented distributed system you can’t afford and can’t debug.
What GPT-5.4 and “extreme reasoning mode” actually are
Strip away the marketing word “extreme” and what’s left is straightforward: longer thinking, bigger memory.
The Information’s scoop (also summarized by Investing.com and others) says GPT-5.4 will offer:
- Up to a 1 million token context window, roughly 2,000 book pages worth of text.
- An “extreme reasoning mode” that lets the model spend far more compute and time on a request, potentially running for hours.
- Better performance on long-horizon, multi-step tasks, keeping constraints straight across many actions, which is exactly what agent frameworks struggle with today.
- A shift toward monthly model updates, not once-a-year events.
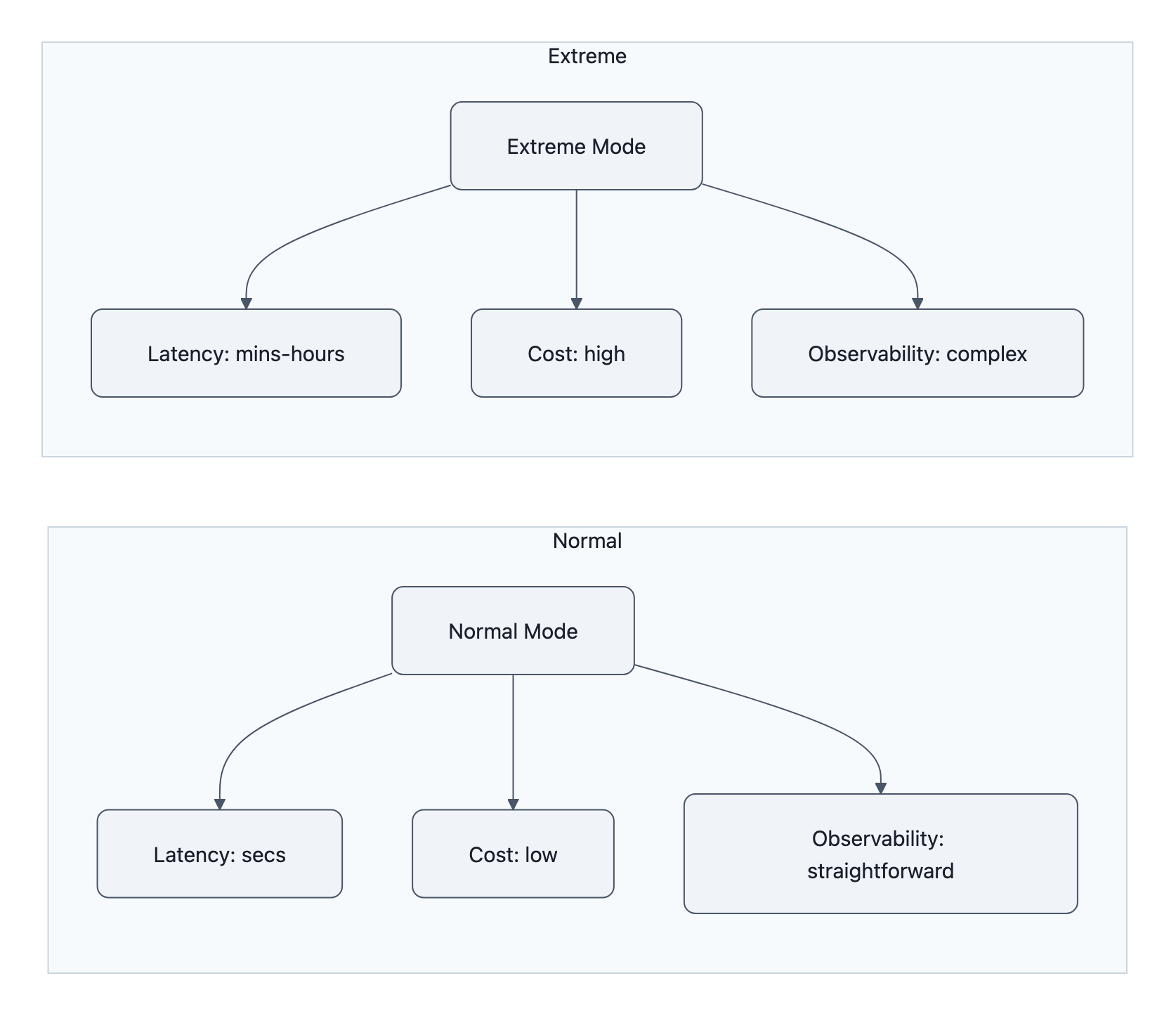
In practice, “extreme reasoning mode” is not some mystical new capability. It’s pay‑per‑thought:
- Higher per‑call cost
- Higher variance in latency (minutes to hours instead of seconds)
- A lot more intermediate state generated on the way to an answer
Think of today’s models as a calculator and GPT-5.4’s extreme mode as renting a grad student for an afternoon. Same brain architecture, wildly different runtime profile.
The 1M context is the other half of the trapdoor. With current long‑context models (Gemini, Claude, GPT‑5 Pro), people are already shoving entire codebases, CRMs, and policy manuals into the prompt. At 1M tokens, you’re no longer “including some docs.”
You’re streaming systems into a single call.
Now combine that with a mode designed to spin on your problem for hours. If you’re still thinking “this is just a smarter GPT‑5,” you’re going to design the wrong product.
Why this is a platform shift: compute-as-feature, not just a smarter model
Most teams currently treat “which model?” as one knob:
gpt-5-instantfor cheap stuffgpt-5-pro(or Anthropic / Gemini equivalent) for “serious” flows
GPT-5.4 forces a different mental model: compute and time become explicit user‑visible features, not hidden infrastructure.
You can already see the shape in the Reddit comment joking about:
GPT 5.4
GPT 5.4 Instant
GPT 5.4 Thinking
GPT 5.4 Thinking Extreme
That’s not just naming snark, that’s the product surface.
We’re heading toward:
- Standard mode: fast, cheap, 10-60 second latency, modest context.
- Deep mode: 5-20 minutes, bigger context, higher reliability.
- Extreme reasoning mode: up to hours, full 1M token context window, eye-watering bills.
In other words, compute tiers start to look like storage tiers in cloud databases.
You don’t just say “use Postgres.” You decide:
- Hot vs cold storage
- Retention policies
- What gets indexed and what doesn’t
GPT-5.4 is that moment for AI: you’ll decide which flows are allowed to request “extreme reasoning,” what their budget is, how often they can retry, and how they checkpoint state.
That’s a huge shift from the “AI wrapper” era. If you’ve read The myth of AI wrappers, this is exactly where the value hides: orchestrating compute, state, and supervision around the model, not slapping a chatbox on top.
The teams that win on GPT-5.4 won’t just “use the newest model.” They’ll:
- Design products that expose compute choices to users (“quick draft vs in‑depth review”)
- Implement schedulers that decide when to escalate to extreme mode
- Build cost-aware agents that know when to stop thinking
That’s platform work, not prompt engineering.
New costs, failure modes, and security risks you should plan for
Long‑runtime reasoning plus 1M tokens doesn’t just scale capability, it scales blast radius.
1. Cost explosions and silent overruns
Imagine an agent that used to finish in 3 minutes on GPT‑5 Pro. Now, with extreme reasoning mode, it sometimes decides “this is hard” and spins for 45 minutes, quietly.
Without hard runtime budgets and kill switches, your monthly invoice becomes a slot machine.
And with OpenAI reportedly moving to monthly model updates, the cost profile won’t even be stable. A minor update might:
- Change how aggressively the model opts into deeper reasoning
- Shift tokenization slightly, affecting how often you hit the 1M token context window
- Alter how verbose intermediate reasoning is, more tokens, more dollars
You already know LLM reliability is messy, see Are large language models reliable for business use?. Now bolt unstable runtime and spend on top.
2. Reproducibility gets harder, not easier
Today, when a model hallucinates, you screenshot the prompt and output and tell your vendor “look at this.”
In the GPT-5.4 world, failures are more like:
- 40‑minute run
- Hundreds of intermediate tool calls
- 600k tokens of mixed user data, third‑party docs, and model‑generated notes
- A subtle misinterpretation at step 27 that poisons everything downstream
Good luck reproducing that three weeks later after two “small” model updates and a few prompt tweaks.
If you don’t start treating LLM calls like long-lived workflows, with checkpoints, logs, and replayable traces, you’ll be stuck in “it broke once and we don’t know why” land.
3. New security and data‑leak surfaces
A 1M‑token long context window encourages people to shove everything into the prompt:
- Full customer histories
- Internal policy wikis
- Live production configs
- Vendor contracts
Now stretch that across hours of reasoning where the model:
- Writes intermediate notes about “interesting edge cases”
- Summarizes internal policies in simplified language
- Synthesizes cross‑customer patterns
Each one of those steps can leak data:
- To logs you don’t realize are sensitive
- To downstream tools you wired in “for convenience”
- To other tenants if isolation is imperfect (remember, we’re still trusting a black box)
And “extreme reasoning mode” is literally designed to create more intermediate state. More steps, more chances to accidentally echo secrets into places you didn’t intend.
From a threat‑model perspective, GPT-5.4 means:
- Bigger prompts to sanitize
- Longer traces to audit
- More powerful “jailbreak surface” (1M tokens of context gives attackers room to stage multi‑step prompt injection)
Treat it like adopting a new database engine you can’t self‑host or inspect, except this database also writes its own queries.
Practical steps product teams and developers must take now
GPT-5.4 is still an unconfirmed scoop. That doesn’t matter. The shape of what’s coming is clear enough to start re‑architecting.
Here’s how to get ahead of it.
1. Treat runtime and context as first-class API parameters
Stop thinking “model = capability.” Start thinking in a struct:
model: gpt-5.x
context_budget_tokens: N
reasoning_tier: { standard | deep | extreme }
max_runtime_seconds: T
Even if your current provider doesn’t expose all these knobs, design your abstraction as if they do. That gives you room to:
- Cap extreme calls per user / per day
- Route some tenants away from long‑running modes
- Swap vendors when someone else offers a better long context window or pricing
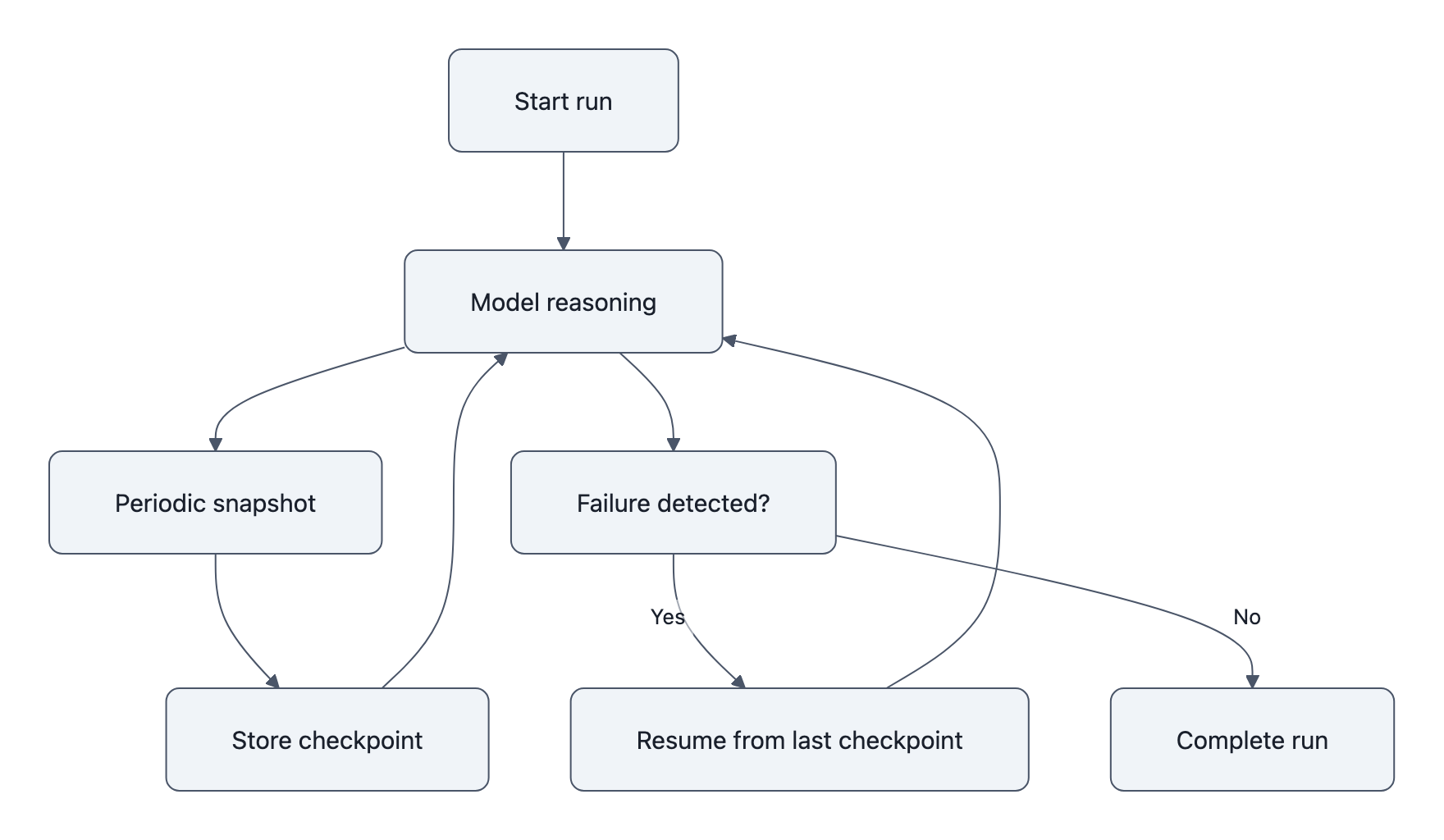
2. Add checkpointing and resumability to agents
Agents today tend to be “fire and forget.” With multi‑hour runs, that’s reckless.
You want:
- Periodic state snapshots: current plan, decisions taken, key context summaries
- Idempotent steps: make each tool call safe to rerun
- Replayable traces: if run #137 fails in minute 43, you can resume from minute 30, not start over
This is where the Agent 1.0 playground kids graduate into workflow engineers.
3. Log like you’re debugging a distributed system
A single extreme reasoning call is effectively a mini distributed system: tools, vector DBs, APIs, the model itself.
You need:
- Structured logs for every tool call, prompt, and model response
- Correlation IDs for the whole run
- Sampling rules, you can’t store every token of every run, but you need enough to reconstruct failures
The goal isn’t “save logs.” It’s make a broken 2‑hour run explainable in 10 minutes.
4. Harden your security posture for 1M‑token prompts
Before you even see GPT-5.4 docs, you can:
- Limit what can go into context: explicit data classification (PII, secrets, internal‑only) and rules about what tiers can see what.
- Strip and scrub: automatic redaction of secrets in both prompts and responses for logging.
- Define per‑tier policies: maybe “extreme reasoning” is only allowed on synthetic / offline data, never live production records.
As long‑context systems mature, we’re going to discover weird leakage channels. You want to be the team that already had mitigations in place.
5. Assume monthly model updates and bake in evaluation
The Information notes OpenAI wants monthly model updates. That kills the old “we’ll do a big evaluation once a year” fantasy.
You’ll need:
- Continuous evaluation suites on your real tasks, not just benchmarks
- Canary traffic for new versions
- Automated rollback when a new monthly model update regresses on your KPIs
LLM reliability goes from “research problem” to SRE practice.
Key Takeaways
- GPT-5.4, with its 1M token context window and extreme reasoning mode, turns model usage into a compute budgeting problem, not just a capabilities checklist.
- Long‑runtime reasoning introduces new cost, latency, and observability challenges that look a lot more like distributed systems than “prompting.”
- A 1M‑token long context window greatly expands the security and data‑leak surface, every extra step and token is a new place to mishandle sensitive info.
- Product teams need to add runtime tiering, checkpointing, and detailed logging now so they can safely exploit GPT-5.4-style capabilities later.
- With monthly model updates, treating LLMs as static “black boxes” is over; continuous evaluation and version‑aware debugging become mandatory.
Further Reading
- OpenAI’s Next AI Model Will Have ‘Extreme Reasoning’, The original The Information scoop on GPT-5.4, 1M context, and extreme reasoning mode.
- OpenAI to Release GPT-5.4 Model With Expanded Context Window, The Information, Republished summary emphasizing the million-token window and agentic use cases.
- GPT‑5.4 Reportedly Brings a Million‑Token Context Window and an ‘Extreme Reasoning’ Mode, Tech blog recap placing the leak in context of other long‑context efforts.
- Tweet with screenshots of The Information story, Public screenshots that kicked off the Reddit discussion.
- Introducing GPT‑5, OpenAI’s official GPT‑5 page, helpful baseline for what’s confirmed versus rumored.
In two years nobody will remember the version number “GPT-5.4,” but they’ll be living with the architectural choices they made when compute became a user‑visible feature. Make those choices on purpose.