
Claude Code token usage does go down if you use fewer words. Just not by much in most real sessions.
Anthropic’s docs say Claude Code counts far more than the line you just typed: system prompt, tool definitions, conversation history, tool inputs, tool outputs, and project memory like CLAUDE.md. That means the folk theory, “write like a caveman and save a ton of tokens”, gets the mechanism backwards. Prompt brevity is a small lever. Session baggage is the big one.
A token is a chunk of text the model reads or writes. Claude Code bills by token consumption, and Anthropic’s cost guide says /usage shows detailed token statistics for the current session. If you want to know what actually changed, that command is better than vibes.
Do shorter prompts actually save tokens in Claude Code?
Yes, directly. Shorter prompts usually mean fewer input tokens for that turn.
But that does not mean total Claude Code token usage drops much. If your prompt is 20 tokens shorter, and Claude Code is also replaying cached instructions, recent history, tool schemas, terminal output, and file contents, then the saving can be tiny relative to the whole request.
There’s a second confusion hiding here: people often mix up input brevity with output brevity. A terse prompt can sometimes nudge Claude toward a shorter reply, but output length depends more on the task, the instructions already in context, and how much tool work Claude decides to do. “Fix failing test in parser” might still trigger file reads, diffs, test output, and a long explanation.
A useful mental model:
| Part of a turn | Does shorter wording help? | Usually large or small? |
|---|---|---|
| Your new prompt | Yes | Small |
| Existing conversation history | No | Often large |
| Tool definitions and system text | No | Fixed/background |
CLAUDE.md and project memory |
No | Can be large |
| Tool output and file content | No | Often very large |
| Claude’s final answer | Sometimes indirectly | Variable |
Anthropic also documents prompt caching for repeated prefixes. Content that stays the same across turns, including the system prompt, tool definitions, and CLAUDE.md, can be cached, reducing cost and latency for those repeated parts. That makes micro-optimizing your phrasing even less likely to be the main win.
What Claude Code counts before you even type
Anthropic’s context-window docs are unusually explicit here. Before you enter a prompt, Claude Code may already load:
CLAUDE.md- auto memory
- MCP tool names
- skill descriptions
- output style instructions
- anything added with
--append-system-prompt
That’s the important bit. Some Claude Code token usage exists before the user contributes a single sentence.
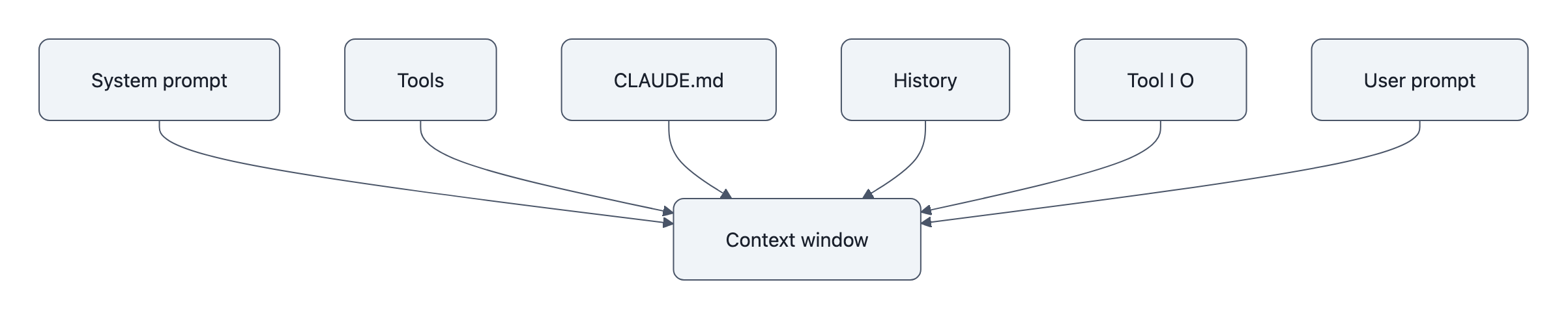
CLAUDE.md is especially easy to miss because it feels like configuration, not conversation. But Anthropic’s memory docs say it is injected into context, and their Advanced Patterns PDF recommends keeping instruction files under 200 lines because longer files consume more context and can hurt instruction adherence.
There’s one neat exception: Anthropic says HTML block comments in CLAUDE.md are stripped before injection. So maintainers can leave human notes there without spending context tokens. That is a much more concrete token-saving trick than replacing “please” with “plz”.
If you’ve seen weird behavior in long coding sessions, this is also where it connects to other failure patterns. A bloated working set can make the model noisier or less reliable, not just pricier, which is part of why tools like Claude Code regression and broader LLM failure modes are worth watching.
Why session sprawl matters more than word count
Claude Code accumulates history across turns. Anthropic says /compact replaces conversation history with a structured summary, which tells you what the real pressure is: not one prompt, but everything the session keeps dragging forward.
A concrete example helps. Imagine two sessions:
| Session | User prompt style | History/tool output | Likely token impact |
|---|---|---|---|
| Fresh session | Verbose | Minimal | Prompt wording matters a bit |
| 40-turn debugging session | Caveman-short | Large test logs, diffs, prior reasoning | History dominates |
Repo with long CLAUDE.md |
Short | Persistent instruction file every turn | Memory dominates |
| Tool-heavy session | Short | Big command output and file reads | Tool output dominates |
This is why people can type almost nothing and still watch usage climb. The model may be rereading a lot of old material and incorporating new tool output every turn.
Subagents are another clue. Anthropic says a subagent can work in its own separate context window, then return only a summary to the main session. That only matters if context size is a real cost driver. It is.
This also overlaps with reasoning controls. If you’re tuning how much effort Claude spends on a task, the savings or cost increase may come from the model doing more or less work internally and through tools, not from shaving a few words off your prompt. That’s adjacent to the tradeoffs in Claude Code reasoning effort.
What users can do instead of writing in cave-people shorthand
Anthropic’s docs point to four levers that matter more than prompt caveman mode.
1. Use /usage and measure.
Claude Code bills by token consumption, and /usage gives per-session stats. The simplest test is to run the same task twice in a clean session, once with a normal prompt, once with a stripped-down one, and compare. Then do the same test again in a long, messy session. That usually makes the bigger driver obvious.
2. Use /compact when sessions get long.
This swaps raw conversation history for a summary. If your session has sprawled, this is one of the few first-party controls designed specifically to cut context load.
3. Keep CLAUDE.md short and clean.
Persistent instructions are convenient, but they ride along in context. Anthropic’s own guidance to keep these files under 200 lines is pretty direct.
4. Trim tool output.
Large terminal output, logs, and file dumps can cost far more than a wordy prompt. If a command prints 2,000 lines and Claude needs only the error summary, the expensive part is obvious.
A practical order of operations:
- Check
/usage - Check what’s loaded with
/context - Compact long sessions
- Shorten persistent instruction files
- Reduce noisy tool output
- Then worry about shaving words off prompts
That last step still helps, just at the margin. Normal English is usually fine.
Key Takeaways
- Claude Code token usage includes much more than the current prompt: system prompt, tool definitions, history, tool inputs and outputs, and project memory.
- Shorter prompts reduce tokens for that prompt, but the savings are often small compared with session history, file context, and tool output.
- Anthropic documents prompt caching for repeated prefixes, which can reduce the cost of stable background context across turns.
/compact,CLAUDE.mdhygiene, and trimming tool output are usually stronger cost controls than writing in ultra-short “caveman” prompts./usageis the clean way to verify changes instead of guessing from how short your prompt looked.
Further Reading
- Claude Code agent loop, What enters the context window and how repeated prefixes are cached.
- Claude Code context window, What loads into context, how history accumulates, and how
/compactworks. - Claude Code costs, Token-based billing,
/usage, and Anthropic’s cost-management guidance. - How Claude remembers your project, How
CLAUDE.mdis handled, including stripped HTML comments. - Claude Code Advanced Patterns PDF, Anthropic guidance on keeping instruction files short and reducing context burden.
The open question is not whether shorter prompts save tokens, they do, but how often that saving survives contact with a real, tool-heavy coding session.