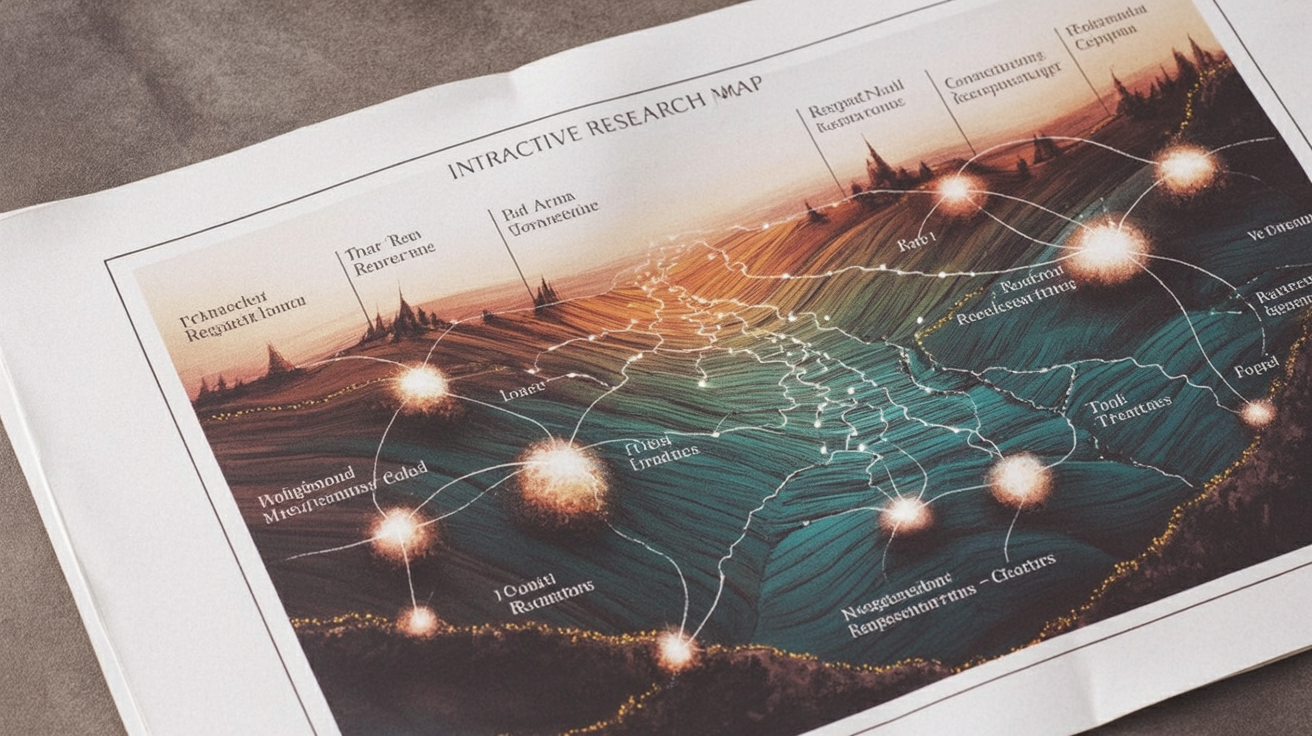
The Global Research Space, a new semantic map tool, is live now as a browser-based alpha that lets people explore 10 million research papers as if they were moving across a map. The public site is up at globalresearchspace.com, and the map view is currently labeled v0.2.0 alpha, with a pan-and-zoom canvas showing floating topic labels spread across clustered regions.
What is confirmed is unusually split across two places. The site itself shows a working product and the map interface; the methodology mostly comes from an April 30 Reddit launch post by the creator, who said the system uses the latest 10 million papers from OpenAlex and turns them into “semantic neighborhoods” for browsing.
What The Global Research Space Actually Is
The homepage describes The Global Research Space in one sentence: “Explore the landscape of the latest research.” Click through to the map and you get a large pan-and-zoom interface with floating topic labels and clustered regions, not a normal search-results page.
That difference matters. A standard paper search tool starts with a query box and returns a ranked list. This semantic map tool starts with position: papers and topics appear to be arranged near related work, so browsing means moving through adjacent areas rather than reformulating keywords over and over.
OpenAlex is a plausible substrate for this. OpenAlex says it is a “map of the world’s research network” and links works, authors, institutions, journals, topics, and more, with hourly updates. Its 2026 roadmap says the database now contains 477 million works, which makes a 10 million-paper slice both substantial and clearly a subset.
On the live map, the directly visible product state is simple: a full-screen map surface, labeled regions, a search-oriented interface around the canvas, and the alpha version badge. That is enough to verify the core claim that this is a working research paper map, not just a mockup or concept page.
How the semantic map tool is built
The current pipeline description is creator-reported, not documented on an official methods page. In the April 30 Reddit launch post, the creator said the system:
- sourced the latest 10 million papers from OpenAlex
- generated embeddings using SPECTER 2
- used titles and abstracts as input
- reduced dimensionality with UMAP
- applied Voronoi partitioning on density peaks
- generated floating labels with a custom labeling pipeline
That is a pretty specific recipe. It is also mostly single-sourced.
Here is the current evidence split for the semantic map tool pipeline:
| Claim | Status | Source |
|---|---|---|
| The Global Research Space exists and is publicly accessible | Confirmed | Product homepage and map page |
| The map page is labeled v0.2.0 alpha | Confirmed | Live map page |
| It uses the latest 10M papers from OpenAlex | Creator-reported | Reddit launch post |
| It uses SPECTER 2 on titles and abstracts | Creator-reported | Reddit launch post |
| It uses UMAP | Creator-reported | Reddit launch post |
| It uses Voronoi partitioning on density peaks | Creator-reported | Reddit launch post |
| Labels are custom and still a work in progress | Creator-reported | Reddit launch post |
| Code is not open source | Creator-reported | Reddit comments |
There is one more useful signal in that launch post: the creator engaged directly with questions about clustering choices. In one exchange, they said they had not considered HDBSCAN and might explore a hybrid. That does not invalidate the current method. It does show the pipeline is still being worked out in public, which fits the alpha label on the site.
What users get from semantic search and analytics
Two things are visible from the live product state and public copy. First, the interface is built around map navigation rather than a flat results page. Second, the creator says the product supports keyword and semantic queries plus analytics for institutions, authors, and topics.
The first part is confirmed by direct observation. The second part is currently creator-reported and only lightly documented on the accessible public pages.
That distinction matters. We can verify that users are being invited to navigate a spatial interface for scientific literature navigation. We cannot yet verify, from public methods documentation, exactly how the analytics are calculated or how semantic retrieval quality compares with a standard search engine.
Implication, with caveat: this kind of semantic paper map is most useful when a researcher knows the area loosely but not the exact keywords. In fast-moving domains, terminology drifts. A spatial interface can help surface nearby work that uses different language for similar ideas. That is a plausible benefit, and it matches the interaction design, but the public site does not yet provide benchmarks showing how often it beats conventional search. For related context on evaluating ML papers in messy, fast-changing domains, see our piece on empirical research in machine learning.
From Query Box to Spatial Browsing
What this launch demonstrates, clearly and directly, is that a live product can turn literature discovery into movement across a terrain. That is the concrete shift here.
The broader pattern did not start with this project. Research mapping interfaces have shown up before in forms like the ArXiv Machine Learning Landscape and other topic-atlas style explorers. What makes The Global Research Space interesting is the combination of scale, public access, and upstream infrastructure: an OpenAlex map-style scholarly graph underneath, then an interface that treats papers as neighborhoods instead of list items.
That is a meaningful product decision. Search boxes are good when users know the term they want. Spatial browsing is better for orientation, adjacency, and “what sits next to this?” exploration. If you want a broader framing for why these systems feel different once the underlying graph is rich enough, our piece on how discovery systems work covers that pattern from another angle.
There is also a very current AI-tooling dynamic here: the interface is shipping before the methods are properly documented. Users can test whether the neighborhoods feel sensible right now. Outsiders still cannot fully audit how those neighborhoods were produced. That split is not unusual anymore, but it is especially important for a paper discovery tool that may influence what researchers read and miss.
Documentation Gaps in the Alpha Release
The biggest missing piece is an official methods page. The live product does not currently provide a detailed public explanation of corpus selection, refresh cadence, embedding infrastructure, clustering evaluation, label generation, or ranking methodology for institutions and authors.
Several important questions are still open:
- What counts as the “latest” 10 million papers? No publication-date cutoff was publicly documented in the accessible pages.
- How often is the map refreshed? OpenAlex updates hourly, but that does not mean this product does.
- How are rankings calculated? The site references analytics, but not the exact formulas.
- How good is the semantic retrieval? No public benchmark compares it with standard academic search.
- How stable are the neighborhoods and labels? The creator described the labeling as a work in progress.
The alpha label on the product is doing real work here. So is the fact that the code is reportedly not open source.
The confirmed picture is narrow but solid: the site is live, the map interface is public, and the alpha badge is visible. The creator-reported picture is more detailed: OpenAlex as source data, SPECTER 2 embeddings, UMAP, Voronoi-based partitioning, and custom labels. What still lacks public documentation is the evaluation layer, refresh timing, ranking formulas, retrieval quality, and evidence that the mapped neighborhoods are stable and useful across real research workflows.
Key Takeaways
- The Global Research Space is a live alpha product that lets users browse research as a pan-and-zoom map rather than a list of search results.
- The core pipeline details are mostly creator-reported, not formally documented on the product site: OpenAlex source data, SPECTER 2 embeddings, UMAP, and Voronoi-based semantic neighborhoods.
- OpenAlex is a credible upstream corpus with 477 million indexed works, making a 10 million-paper slice plausible but still partial.
- The interface changes the discovery workflow from keyword lookup to spatial exploration, which can be useful for surveying unfamiliar or fast-moving fields.
- What is still missing is evaluation and documentation: refresh cadence, ranking methods, retrieval quality, and clustering choices are not yet publicly specified in depth.
Further Reading
- The Global Research Space map, Live product page showing the alpha map interface and current product state.
- The Global Research Space homepage, Canonical homepage for the product with its short public description.
- OpenAlex help: How does OpenAlex work?, OpenAlex’s explanation of its research graph and update cadence.
- OpenAlex 2026 roadmap, Scale context for the underlying corpus, including the 477 million works figure.