
If you tried to copy Nvidia’s Nemotron 3 stack inside your own startup, the first nasty surprise would be the bill: $26 billion worth of multi-year cloud service commitments is what Nvidia has lined up for itself to fuel DGX Cloud and model R&D. That’s the line that underpins all the hype about Nvidia open-weight models.
The important part: that $26B is not a donation to “open source.” It’s a bet that giving away the models will sell more of the pipes.
TL;DR
- Nvidia open-weight models are designed to make software feel free so hardware and DGX Cloud become the default place to run them.
- The $26B commitments are cloud rental (per the 10‑Q), but Nvidia is lining that capacity up behind Nemotron and DGX, not your random colo.
- For builders, “open” will get cheaper, but only if you accept deeper Nvidia hardware lock-in, and that should change both product and policy decisions.
Reality Check: What the SEC Filing Actually Says About the $26B
First, precision.
Nvidia’s 10‑Q says: “Multi-year cloud service agreement commitments … were $26 billion” and notes those are expected to support R&D and DGX Cloud offerings. Full stop. No “we will spend $26B to build open-weight models” in the legal text.
WIRED then talks to Nvidia execs, stitches that line together with Nemotron 3, and comes out with: “$26B to build open-weight AI models.” That’s journalism synthesis, not literal accounting language.
So what’s actually going on?
- On paper: Nvidia is pre‑buying server capacity from providers (CoreWeave alone says its contract is ~$6.3B).
- In practice: that capacity is pointed at training and hosting models that are:
- Tuned for Nvidia GPUs and networking
- Released as open weights (Nemotron 3 Super/Ultra/Nano)
- Wrapped in Nvidia software (CUDA, TensorRT‑LLM, DGX Cloud)
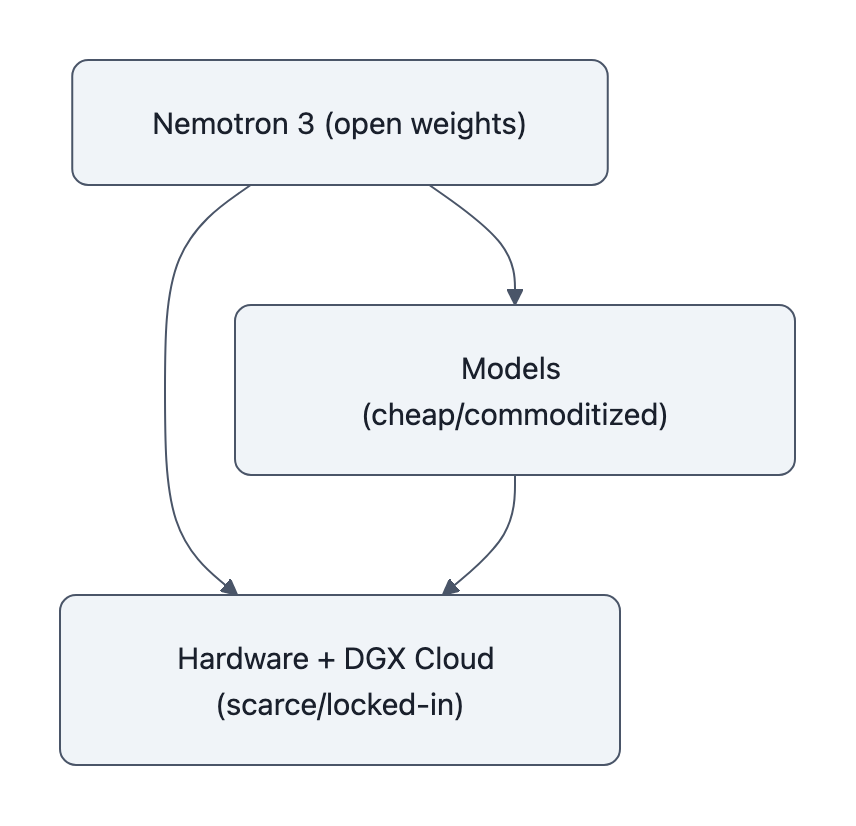
The key insight: Nvidia is using cloud commitments to subsidize a reference stack, models + tooling + hosting, that normalizes running “open” on Nvidia, not on some neutral substrate.
That’s the lock-in move.
Why Nvidia Open-Weight Models Are a Strategic Lock-In

If you were Nvidia and you wanted to keep CUDA the default target for every serious AI workload, you’d do three things:
- Make sure the best “free” models run stupidly well on your hardware.
- Publish the weights so everyone benchmarks and fine‑tunes on your stack.
- Offer a fully managed cloud path (DGX Cloud) for the people who don’t want to think.
That’s exactly what Nemotron 3 is.
Nemotron 3 Super (128B params) and friends ship as open models, but the docs read like a recipe book for “How to extract maximum throughput from Nvidia GPUs”:
- Training and inference configs tuned for H100/GB200.
- Reference implementations with TensorRT‑LLM and CUDA primitives.
- Model cards and benchmarks run on Nvidia hardware.
If you’re a startup, the path of least resistance becomes:
git clone→ follow Nvidia’s optimized config → deploy on DGX Cloud or an H100 cluster → brag about your “open” stack.
The tradeoff they’re making:
- What you gain:
- High-quality, open weights you didn’t pay to train.
- Battle‑tested configs.
- Easy scale‑up if you stay inside DGX Cloud and Nvidia tooling.
- What you give up:
- Portability, your entire infra, from model to serving stack, is designed around Nvidia hardware assumptions.
- Negotiating power, once your product depends on GPU‑specific kernels and DGX quirks, it’s harder to move to cheaper or non‑Nvidia options.
This is the twist: open weights are being used to commoditize models faster than hardware. Once models feel free and interchangeable, all the marginal value (and pricing power) flows to the infrastructure you can’t easily swap out.
What This Means for Startups, Clouds, and Open AI Labs
Let’s walk through how this plays out for each group.
Startups: cheaper models, more expensive exits
A product team building on Nvidia open-weight models sees lower up‑front costs:
- You don’t train the base model.
- You fine‑tune Nemotron 3 variants with off‑the‑shelf recipes.
- You deploy via DGX Cloud or Nvidia‑optimized clusters.
Your unit economics improve on day one. But your platform risk quietly spikes:
- Re‑targeting to another vendor means re‑doing perf work, quantization, kernels, observability.
- If Nvidia raises prices on DGX Cloud or hardware availability tightens, that flows straight into your margins.
So your valuation story becomes:
- “We own distribution / workflow / UX,” not “we own IP in the models.”
- You’re negotiating with investors and buyers who know you’re an Nvidia‑shaped SaaS.
Open weights make the P&L look better short‑term and the bargaining position worse long‑term.
Cloud providers: friend today, undercut tomorrow
Those $26B multi-year cloud service commitments mostly go to partners, CoreWeave, others. Great business if you’re renting Nvidia GPUs back to Nvidia.
But long term?
- Every Nemotron‑based workload that leans on DGX Cloud is one less reason to default to generic hyperscaler infra.
- If you’re AWS/Azure/GCP trying to push custom silicon (Trainium, TPU, etc.), Nvidia’s “free” models are a problem, they make it harder to convince customers to pick your not‑Nvidia chips.
The tradeoff for clouds:
- Take Nvidia’s money now (capacity contracts, co‑marketing).
- Or push harder on your own model stacks and open platforms that decouple software from Nvidia hardware.
If you don’t do the latter, you’re willingly turning your cloud into a very fancy Nvidia resale channel.
Open AI labs (especially outside the US): arms race, but on Nvidia’s map
Chinese labs releasing open-weight models (DeepSeek, Alibaba, etc.) have been the default substrate for a lot of global startups.
Nvidia’s move hits them in two ways:
- Benchmark politics: Nemotron 3 is explicitly framed against GPT‑OSS and Chinese models; Nvidia is trying to set the “good enough and free” bar on its own terms.
- Tooling gravity: if everyone’s fine‑tuning with Nvidia’s recipes, even non‑Nvidia weights are likely to be evaluated and deployed in Nvidia‑centric pipelines.
You can win some benchmarks and still lose the war if your users are all running on your competitor’s hardware.
What Builders and Policymakers Should Do Next
Here’s the part that actually changes how you should behave.
If you’re a product team
Treat Nvidia open-weight models like you would a generous cloud credit program: great accelerator, hidden strings.
Concrete steps:
- From day zero, keep a portability budget:
- Don’t hardcode Nvidia‑only ops in your core business logic.
- Abstract serving so you can at least A/B test on non‑Nvidia infra.
- Track effective cost per 1M tokens across:
- DGX Cloud + Nemotron 3
- A non‑Nvidia cloud + open models
- Any in‑house / on‑prem rigs
You don’t have to be neutral today. You do want an exit hatch.
And when you pitch “we’re open‑source based,” be honest with yourself: are you open in the way that matters (infra), or just at the model checkpoint level?
If you’re a researcher or open lab

Use Nvidia’s money, don’t let it fully shape your roadmap.
- Mirror critical models (including Nemotron derivatives) with portable training/inference configs that run on at least one non‑Nvidia stack.
- Publish hardware‑agnostic benchmarks where the primary axis is FLOPs / dollar or latency / watt, not just raw scores on Nvidia hardware.
The more “open” quietly means “runs best on CUDA + DGX,” the less open it really is.
If you’re a regulator
Regulators shouldn’t get hypnotized by the word “open.”
The 10‑Q already tells you the real choke point: multi-year cloud service commitments tied to R&D and DGX Cloud.
Questions worth asking:
- Are open-weight releases being used to entrench a single vendor’s position in inference and hosting?
- Is there effective interoperability for major “open” models on non‑Nvidia hardware?
- Do cloud commitments and exclusivity terms (CoreWeave, others) materially limit competitors’ access to high‑end GPUs?
This is less about “is the model card on GitHub?” and more about “who controls the only practical way to run it at scale?”
Key Takeaways
- The SEC filing does not literally say “$26B for open-weight models”; it’s $26B in cloud service commitments backing R&D and DGX Cloud.
- Nvidia open-weight models, especially Nemotron 3, are tuned to make Nvidia hardware and DGX Cloud the default inference target.
- This accelerates model commoditization while deepening Nvidia hardware lock-in, shifting value from software to infrastructure.
- Startups get cheaper, better models now but increase long‑term dependence on Nvidia’s stack and pricing.
- Builders should design for portability and regulators should focus on infra control, not just whether weights are “open.”
Further Reading
- Nvidia Will Spend $26 Billion to Build Open-Weight AI Models, Filings Show, WIRED, How WIRED connects the 10‑Q line to Nvidia’s open-model push and Nemotron 3.
- NVIDIA Corporation Form 10-Q (Quarter Ended Oct. 26, 2025), SEC, The primary source for the $26B “multi-year cloud service agreement commitments.”
- NVIDIA Debuts Nemotron 3 Family of Open Models, NVIDIA Newsroom, Nvidia’s technical and marketing story for Nemotron 3 open models.
- Nvidia to spend $26bn on cloud computing capacity over six years, DataCenterDynamics, Trade coverage framing the $26B as server rental across cloud partners.
- CoreWeave Says Nvidia Cloud Contract Valued at $6.3 Billion, Bloomberg, Deal‑level view of how those commitments show up in individual cloud provider agreements.
Nvidia’s move is not “yay, more open models” or “boo, more lock‑in.” It’s both, on purpose. The smart response is to cash the openness dividend, while keeping your architecture ready to walk away if the shovel vendor starts charging by the breath.
Also worth reading for more context on Nvidia open-weight models and agent stacks:
– Nvidia open-weight models and CUDA agents
– How Nvidia open-weight models change AI builds