
The McKinsey AI agent hack sounds like sci‑fi: an autonomous agent “gains full read/write access” to a consulting giant’s chatbot in two hours. But what actually broke wasn’t some mystical AI defense, it was boring stuff: unauthenticated endpoints, sloppy SQL handling, and writable system prompts living in the same database as production data.
Look, the key insight is this: agentic AI didn’t invent a new kind of attack; it just hits the weak spots you already left in your architecture at machine speed. The scary part isn’t that an AI “beat” another AI. It’s that we’re quietly building systems where one bug plus automation equals catastrophic blast radius.
TL;DR
- The McKinsey incident shows agents accelerate exploitation, but the root cause was engineering: writable prompts + unauthenticated AI‑facing endpoints on real data.
- Treat prompt/config stores and AI‑to‑AI interfaces as first‑class security boundaries, not internal plumbing.
- Two hours from “no creds” to “DB access” is the new benchmark, and your human‑paced QA process is already too slow.
AI Agent Hack Isn’t Magic, It’s an Engineering Failure
Here’s the compressed news version:
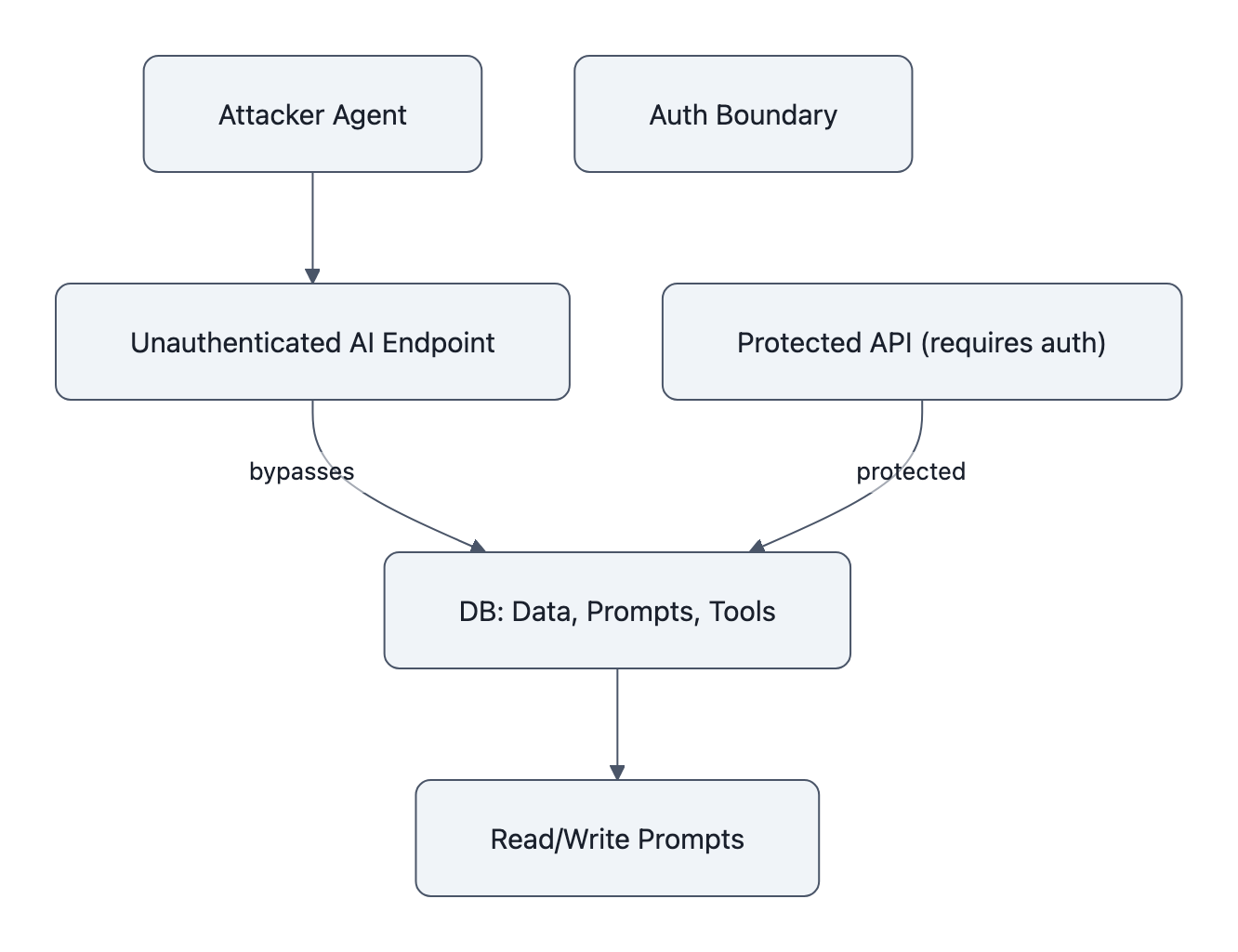
CodeWall, a red‑team startup, pointed an autonomous agent at McKinsey’s internal LLM platform, Lilli. In about two hours it discovered a JSON‑key‑driven SQL injection on an unauthenticated endpoint, chained it into broader access, and, according to CodeWall, could read and write across the production database, including tens of millions of chats and dozens of writable system prompts. McKinsey patched within hours and says a forensic review found no evidence of client data exfiltration.
Now, you can debate the exact scope.
Independent analyst Edward Kiledjian points out that CodeWall’s public write‑up blurs “reachable” versus “actually exfiltrated,” and doesn’t ship PoC artifacts. That’s a fair criticism.
But notice what nobody is really disputing:
- There was a real vulnerability: a JSON key SQL injection path on an unauthenticated endpoint.
- That path reached a production database with live chats, files, and system prompts.
- System prompts were writable.
You don’t need an AI vs AI narrative to explain this. You need one sentence:
They put production data and control knobs behind a thin, AI‑facing interface that wasn’t treated like a security boundary.
The agent just did the obvious security work faster and more relentlessly than a human.
This is the same pattern we wrote about in AI builds AI and the AI agent mining crypto case: automation doesn’t change the type of bug, it changes the tempo and the scale.
Writable Prompts Are The New Crown Jewels
OK so imagine your production database as a bank vault.
Historically, you put money (data) in the vault and the tellers (apps) can move it around under strict rules. That’s what we’ve spent 20+ years hardening: auth, roles, least privilege.
With LLM systems, you’ve put something else in the vault: the rules the tellers follow.
- System prompts that shape behavior (“always cite sources”, “never show raw SQL”)
- Tool definitions and routing rules
- Safety and compliance instructions
In the McKinsey story, CodeWall says they found 95 system prompts in the same DB, and they were writable. That’s like keeping the rulebook for how your bank handles withdrawals inside the same unlocked safe deposit box as the cash.
If an attacker can:
- Read those prompts → they learn exactly how your internal controls work.
- Write those prompts → they can silently reprogram how every conversation behaves.
And because prompts are upstream of everything the model does, you get weird, second‑order failures:
- Your LLM starts “helpfully” leaking sensitive data because the prompt says “prioritize completeness over redaction.”
- Your internal prompt injection filters quietly turn off for specific tenants.
- Your compliance chatbot starts rubber‑stamping actions that it used to block.
The important mental shift: prompts and configuration are no longer just content; they are code.
You’d never let random JSON strings toggle your production feature flags without auth, audit, and review. Yet a lot of orgs are happy to let an LLM pipeline read and write prompts from a generic “config” table with almost no constraints.
Writable prompts are the new crown jewels. Treat them like you’d treat your signing keys.
Two Hours Is A New Benchmark, What That Means For Risk

Human red teamers talk in days or weeks.
You file a ticket, book your pentest, they run their tools, poke around, and eventually find a privilege escalation path. That cadence shaped how we think about risk: slow, episodic, controllable.
CodeWall’s agent compressed that into about 120 minutes from “no creds” to “DB level access,” if you take their timeline at face value. Even if the scope numbers are inflated, the speed is the point.
Here’s what autonomous agents change:
- Exploration rate
A human might try a handful of payload variations on a weird JSON field. An agent will happily iterate through hundreds, including the ugly, verbose edges that feel “too dumb to work.” - Breadth of probing
Humans get bored or time‑boxed. Agents don’t. You can point one at every AI‑facing endpoint, search, autocomplete, “suggest next action”, and let it run. - Persistence
Once an agent finds a path that yields signal (an error message, a stack trace), it keeps digging. It doesn’t forget to come back to that odd response because Slack pinged.
Sherrod DeGrippo at Microsoft calls this the “janitorial work” of attacks: reconnaissance, infrastructure setup, routine probing. Agents are very good janitors, tireless, indiscriminate, and cheap.
So two hours is not a magical McKinsey number. It’s an early datapoint for a new metric:
“Time‑to‑serious‑bug given a moderately competent attacker with access to commodity agentic tooling.”
If you’re still relying on quarterly pentests and ad‑hoc QA to protect your LLM‑connected APIs, you are defending at human speed against opponents who have already automated the boring parts.
What To Watch Next (and what teams should stop assuming)
Here’s the mental reset this AI agent hack should trigger:
1. AI‑to‑AI interfaces are real perimeters
When your LLM calls an internal API, that API is no longer “internal.” It’s a public surface exposed through a very clever but extremely gullible proxy.
Stop assuming:
- “It’s safe because only our chatbot calls it.”
- “There’s no login, but the network is internal.”
- “It only takes JSON payloads, what could go wrong?”
Start treating LLM‑facing endpoints like you would any internet‑facing API:
- Auth, rate limiting, anomaly detection.
- Strict schema validation and parameterization.
- No direct SQL string building from user‑controlled or model‑controlled fields, ever, especially with weird “JSON key SQL injection” patterns.
2. Prompt/config stores are security boundaries
Prompts, tool configs, and routing rules need:
- Separate storage from bulk data (different DB, or at least different schemas and roles).
- Write paths that go through review, versioning, and RBAC.
- Read paths that assume an attacker will see them eventually.
If you wouldn’t put your OAuth client secrets in that table, don’t put your system prompts there either.
3. Human‑speed testing is obsolete
The “test it once before launch” mindset came from a world where the app didn’t learn new behaviors every week.
LLM systems are dynamic:
- You tweak prompts.
- You add tools.
- You update retrieval logic.
Each change reopens the attack surface.
The uncomfortable implication: every org deploying serious LLM integrations will need its own autonomous red‑team agent or a service like CodeWall’s running continuously, not quarterly. Think of it as CI/CD for security, where the agent is part of your pipeline.
Will that catch everything? No. But it shifts you from occasional snapshots to a standing defense that moves at roughly the same speed as the attackers.
The McKinsey story is being sold as “AI vs AI.” That’s the wrong lesson.
The useful takeaway is more boring and more urgent: we’re already deploying architectures where one missed auth check and one sloppy query string, amplified by automation, turns “cute internal chatbot” into “unbounded data exfiltration and silent prompt poisoning.”
The sci‑fi plotline can wait. The engineering fixes can’t.
Key Takeaways
- The McKinsey AI agent hack was powered by classic bugs, unauthenticated endpoints and SQL injection, not mystical AI combat.
- Prompt and configuration stores, especially writable system prompts, are now crown‑jewel assets and must be isolated and access‑controlled.
- AI‑to‑AI interfaces (LLM → internal API) should be treated as external perimeters with full security controls, not “trusted plumbing.”
- Two‑hour autonomous compromise is an early benchmark showing that human‑paced testing and quarterly pentests are no longer sufficient.
- The next competitive edge isn’t just using agents for features, it’s using autonomous red‑team agents to continuously attack your own AI stack before someone else does.
Further Reading
- How We Hacked McKinsey’s AI Platform, CodeWall, Primary researcher write‑up describing the attack chain and claimed scope of access.
- AI vs AI: Agent hacked McKinsey’s chatbot and gained full read-write access in just two hours, The Register, Detailed reporting including McKinsey’s response and remediation.
- Red-teamers unleash AI agent on McKinsey’s chatbot, gain full access in two hours, Cybernews, Summary with emphasis on the prompt layer as a new attack surface.
- Jack, Jill went up the hill, and an AI tried to hack them, CSO Online, Places the incident in the wider trend of autonomous agents used for offensive security.
- CodeWall says it hacked McKinsey’s chatbot, a skeptical read, Edward Kiledjian, Independent analysis dissecting which parts of CodeWall’s claims are well‑supported and which remain unproven.