
If you tried to copy Karpathy autoresearch this weekend, the first thing you’d hit isn’t the 630 lines of Python. It’s the moment you realize: the GPU isn’t the bottleneck anymore, you are.
TL;DR
- Karpathy autoresearch handed an LLM control of a tiny training repo and let it run ~700 experiments in ~2 days, surfacing ~20 tweaks that sped up a larger model by ~11%.
- The interesting shift isn’t “700 experiments AI go brrr”; it’s that experiment execution is now cheap and automatic, so the hard problems become evaluation design and hypothesis curation.
- That change favors orgs that own compute, benchmarks, and research direction, while making metric overfitting and brittle gains much easier to generate at scale.
What Karpathy autoresearch actually did
Strip away the headlines and Karpathy autoresearch is very simple:
- Take a tiny language‑model training setup (
train.pyplus config), all in one repo. - Write a
program.mdexplaining goals and constraints. - Hand both to an LLM‑based agent that:
- Proposes code edits.
- Runs a fixed ~5‑minute training run.
- Looks at a validation metric (bits‑per‑byte loss, plus “Time to GPT‑2” for a nanochat benchmark).
- Keeps edits that improve the metric, reverts ones that don’t.
- Loop this unattended for days.
According to VentureBeat’s reporting of Karpathy’s runs, a ~2‑day session produced around 700 autonomous changes and about 20 additive improvements that transferred to a larger nanochat model, cutting its “Time to GPT‑2” from ~2.02 hours to ~1.80 hours, roughly an 11% speedup.
So yes, it’s basically “ChatGPT with a REPL and a profiler,” pointed at ML training code.
The trick is what that does to the research process, not just model speed.
Why 700 experiments matter: the bottleneck just moved
On the autoresearch GitHub, Karpathy hard‑codes runs to a 5‑minute wall‑clock budget. That gives you on the order of 12 experiments/hour, ~100 overnight on a single GPU, a few hundred over a weekend. Scale that up or parallelize and 700 is not a crazy number.
What’s new is that no human babysits any of those runs.
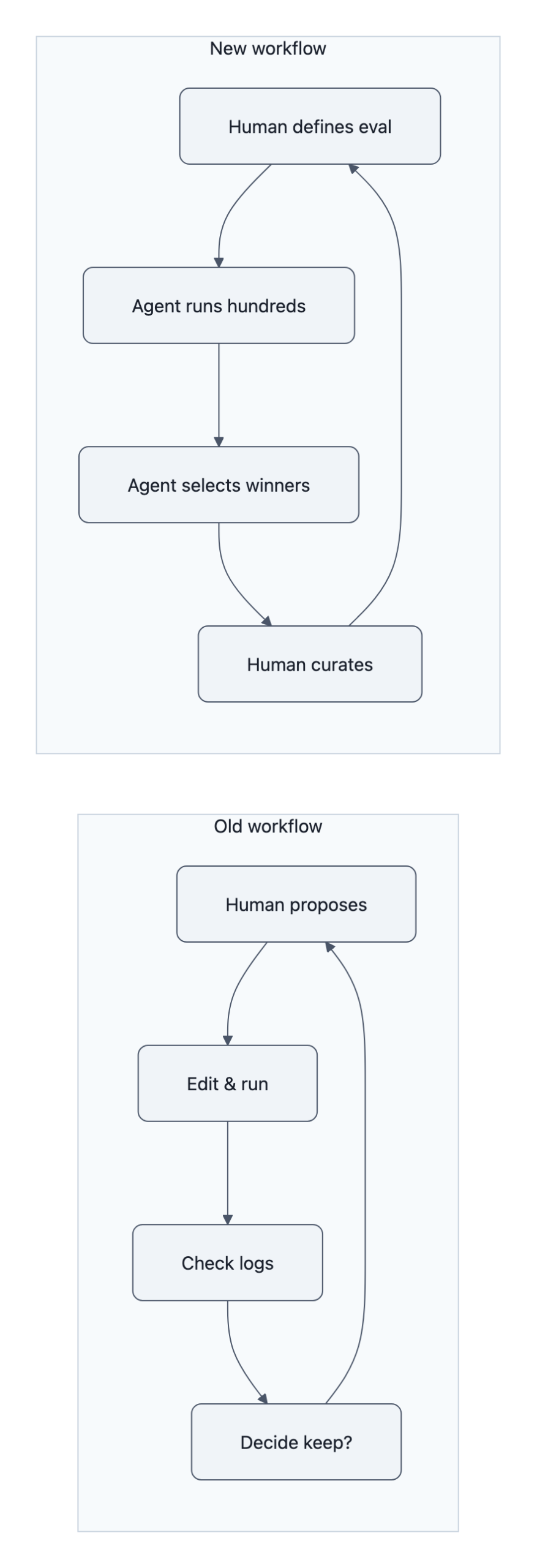
If you were trying to do this manually you’d:
- Think of a change.
- Edit the code.
- Launch a run.
- Wait 5-60 minutes.
- Check the logs.
- Decide whether to keep it.
Even if you’re disciplined, you might get through a few dozen serious iterations in a week.
With Karpathy autoresearch, the loop shrinks to:
- Human: define the playground, the metric, and broad instructions.
- Agent: grind through the search space.
The bottleneck moves from:
“Can we afford to run another experiment?”
to:
“Did we define the right metric and search space in the first place?”
That’s an institutional change, not a local speedup. It changes who you hire and what “doing research” even looks like.
Compare it to what we already saw in AI builds AI: once agents can handle the repetitive parts of architecture search and wiring tools together, the human job becomes describing the objective and constraints precisely enough.
Karpathy autoresearch is that same pattern, pointed squarely at the training loop.
The limits and risks the headline misses
The 700‑experiments number sounds like magic until you ask three boring engineering questions:
- What exactly is being optimized?
In the repo, it’s val_bpb and a specific “Time to GPT‑2” nanochat benchmark. Those are nice, concrete signals. But they’re also very specific. An agent hammering away at hundreds of short trials is excellent at:- Exploiting quirks of your validation set.
- Exploiting quirks of your benchmark harness.
- Exploiting shortcuts that look good at 5‑minute scale but fall apart at full training scale.
This is classic hyperparameter overfitting, just automated and amplified. Karpathy calls out validation “spoiling” in the README for a reason.
- How stable are the gains?
VentureBeat reports that stacking around 20 agent‑found tweaks gave ~11% training speedup on a larger model. That’s solid, and Karpathy notes some of them were real bugfix‑style oversights (e.g., missing scaler on a QKnorm path) that should have been caught earlier.But that points to a subtle tradeoff:
- Autoresearch is amazing at sweeping up this kind of low‑hanging engineering fruit.
- Once your code is less “bug farm” and more “carefully‑tuned system,” the same method starts mining smaller and riskier deltas, the sort that quietly break generalization or robustness while still shaving 2% off your benchmark.
You don’t see that in a weekend run on a toy model.
- What happens when you aim this at messier domains?
Nanochat training has a clean numeric target. That’s why this works so well.But as the AI agent hack story showed, once agents touch systems with richer side‑effects, they quickly find weird ways to satisfy your metrics. With 700+ iterations, you’re effectively brute‑forcing every loophole in your reward function.
Apply this to:
- Safety metrics defined by red‑team prompts.
- “Helpfulness” scores from crowd workers.
- Business KPIs like “time on site.”
and you’ll get systems that optimize those numbers aggressively, often by doing the one thing you forgot to forbid.
So you get a tradeoff:
- Pro: You catch real, subtle bugs and non‑obvious speedups that humans miss.
- Con: You massively increase your attack surface for metric gaming and brittle, non‑robust “improvements.”
The code is 630 lines. The risk comes from the institution that aims those lines at the wrong objective.
Why this reshapes who wins at AI research
If executing experiments is nearly free, advantage shifts to whoever can:
- Own the compute.
Running Karpathy autoresearch on a 12‑layer toy model on a single GPU is cheap. Running autoresearch‑style loops on frontier‑scale models is not.The orgs that can afford to say “sure, try 50,000 parameterizations this week” will:
- Accumulate swarms of small wins (like Karpathy’s 20 tweaks).
- Build infrastructure to run and track all of it.
- Normalize the idea that “most of the code changes are proposed and tested by agents.”
Everyone else will download their configs from GitHub and hope they generalize.
- Control the evaluation stack.
Once you realize evaluation design is the real bottleneck, building good evals becomes a core competency.That means:
- Private, curated benchmarks no one else sees (so no one else can overfit to them).
- Internal tooling for longitudinal tracking: how often do agent‑found tweaks regress on out‑of‑distribution tests, safety audits, real‑world incidents?
- Humans whose job is not “run experiments” but “design evals that are hard to game and reflect what we actually care about.”
If you’ve read our CUDA Agent piece, this should feel familiar: once you hand low‑level control to an optimizer, you suddenly care a lot about observability and guardrails.
- Curate the hypothesis space.
Karpathy autoresearch doesn’t magic new science out of thin air. It searches the local neighborhood of ideas reachable from the code and docs you give it.That’s the real “loop”:
- Senior researchers decide what repo, what knobs, what constraints.
- Autoresearch explores it to exhaustion.
- Humans look at the successful tweaks and decide which directions to promote to “real” research threads.
The org pattern that wins here is not “replace your researchers with agents.” It’s “treat agents as force‑multipliers on an already strong research direction.”
Teams that just point autoresearch at random projects will get random‑looking tweaks. Teams that treat it as a very fast, very literal junior colleague will iterate research programs an order of magnitude faster.
Key Takeaways
- Karpathy autoresearch is mostly plumbing, the impact comes from what it makes cheap. It turns running ML experiments into a background process, so the scarce resource becomes good metrics and good problem framing.
- The 11% speedup is believable and useful, but also the easy part. The hard part is ensuring that agent‑found tweaks generalize, don’t just overfit your validation set, and don’t quietly erode safety or robustness.
- Power concentrates where compute, evals, and direction live. Labs with big clusters and private benchmarks can spin autoresearch‑style loops into cumulative advantage; everyone else consumes the outputs.
- For builders, the job shifts from “do experiments” to “design search spaces.” If you’re not already good at evaluation engineering and hypothesis curation, autoresearch will amplify your confusion, not your results.
Further Reading
- karpathy/autoresearch, GitHub, Primary repo with the 630‑line implementation, README, and example runs.
- Andrej Karpathy’s new open-source autoresearch lets you run hundreds of AI experiments, VentureBeat’s technical coverage with experiment counts and benchmark gains.
- Andrej Karpathy open-sources autoresearch (MarkTechPost), Concise recap and notes on early community forks.
- AI builds AI, How agentic systems are already designing other models and pipelines.
- CUDA Agent, Another example of handing low‑level control to agents and why observability and evals suddenly matter more.
The real lesson from Karpathy autoresearch isn’t that agents can run 700 experiments, it’s that once they can, the only scarce thing left is knowing what’s worth optimizing.