
A developer closes a chat window after twenty careful minutes of setup. The assistant now knows the project name, the coding style, the fragile deployment ritual, the one vendor API that always times out on Fridays. Then the window disappears, and all of it goes with it. That ordinary little amnesia is the real backdrop for the sudden attention on AI memory system products.
MemPalace is just the entry point: an open-source, local memory layer for LLMs and agents, built around ordinary components, with a benchmark story loud enough to travel and disputed enough to deserve caution. The more important fact is simpler: in agent products, memory architecture, not model IQ, is becoming the real moat, and local inspectable memory changes user power more than disputed benchmark wins do.
Once you see that, the celebrity angle barely matters. The real question is who owns the notebook your assistant keeps, whether you can read it, and whether you can take it with you when the model underneath changes.
MemPalace Is Not the Point: Persistent Memory Is
A lot of assistants still feel like brilliant temp workers. They can do sharp work in the meeting, then leave the building with no memory of how your team actually operates. That is not mainly a model problem. It is what happens when people confuse a larger context window with memory.
A context window is just the amount of text a model can keep in its head at once. Think of it as a bigger kitchen table. You can spread out more papers on it, but you still do not have folders, labels, or a filing cabinet. Persistent context is the filing cabinet: facts stored outside the model, organized so the right ones come back later.
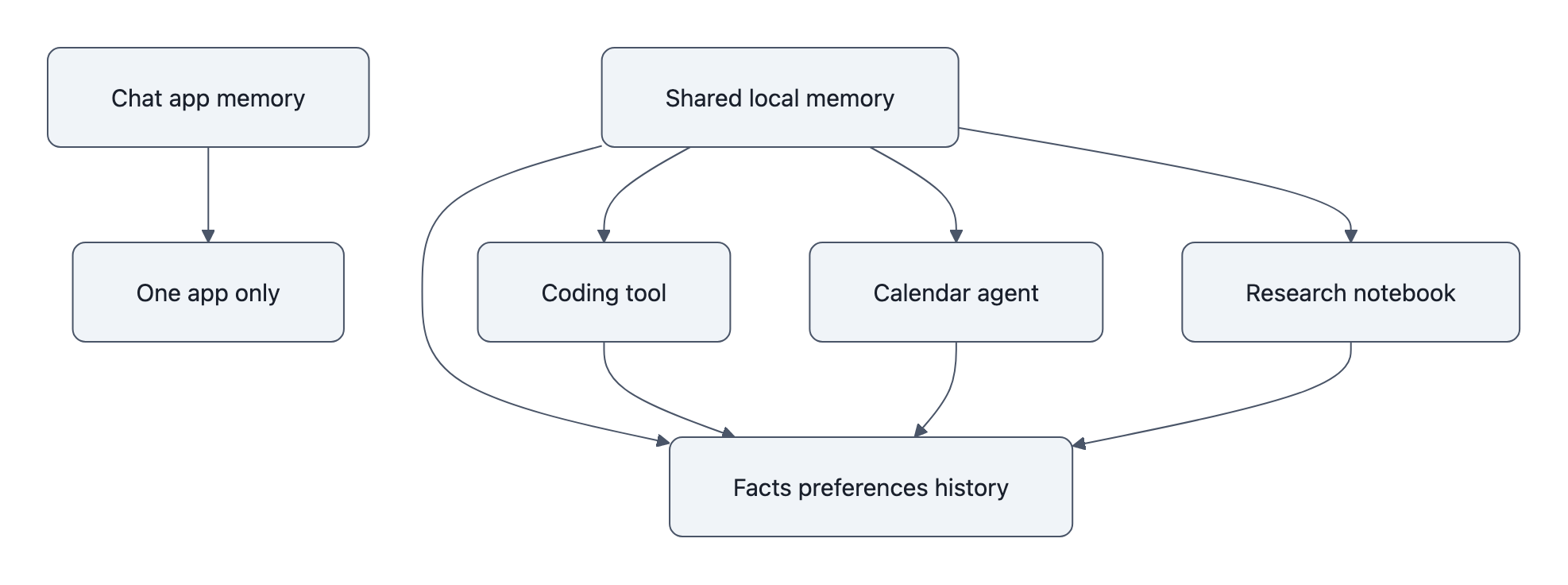
The difference gets obvious in a real week. Imagine the same person using three tools: a coding assistant, a calendar agent, and a research notebook. In the coding tool, they explain that the team ships on Tuesdays, prefers Python, and has one ancient billing service nobody wants to touch. In the calendar tool, they mention they are traveling next Thursday and cannot deploy then. In the notebook, they collect notes on PCI compliance because that billing service is becoming a problem.
A bigger prompt helps only inside whichever app is open. A reusable memory layer connects the dots across all three. Next time the coding assistant proposes a release plan, it does not need the whole ritual typed out again. It already knows Tuesday is sacred, Thursday is blocked, and compliance work is shaping engineering priorities.
That is why MemPalace is interesting. Not because it promises a chatbot that “never forgets,” but because it points toward a separate memory layer, local, inspectable, reusable across tools. Once memory sits beneath the app instead of inside a single chat product, the moat moves downward in the stack.
A chat interface is easy to copy. A memory layer full of useful, portable history is not.
Why an AI Memory System Breaks in Real Use
I spent way too long reading about memory systems, and the pattern is almost comically consistent: the demos look clean, then real life arrives with allergies, deadlines, stale notes, and weird human boundaries.
Start with wrong-scope retrieval. You tell an assistant your daughter has a peanut allergy while planning a school event. Two days later you ask for restaurant ideas, and it recommends places without filtering for allergies. Or worse, it drags that family detail into a work context where it does not belong. The failure is not “the model forgot.” The failure is that the system did not know when that memory should return. Builders need scope rules, work, personal, project, temporary, and retrieval logic that asks not just “Is this related?” but “Is this appropriate here?”
Then there is stale memory. A developer stores a note in March: “Deploy through the old billing gateway.” In April the migration finishes. In May the agent still keeps surfacing the old path like a ghost in the vents. That is how a helpful memory becomes a trap. Durable memory without decay is just rot with excellent search. Builders need timestamps, expiration rules, confidence scores, and ways to downgrade or archive facts that have gone soft.
The third failure is poisoned memory. An agent reads a malicious tool output, a bad summary, or a user-injected instruction and stores it as if it were trusted ground truth. After that, every future session bends a little around the contamination. This is one reason teams work so hard to reduce LLM hallucinations: retrieval mistakes do not just make systems forgetful, they make them confidently wrong. And once memory starts driving actions, the problem starts to rhyme with the brittle failure patterns behind the AI agent hack. Builders need provenance, where a memory came from, when it was stored, which tool produced it, and whether it has been verified.
That is the practical case for local memory. If the memory lives in your environment, SQLite tables, vector indexes, logs you can inspect, you can at least see the bad note, trace it, delete it, and ask why it was retrieved. If it lives behind a vendor curtain, you are arguing with a ghost.
What MemPalace Suggests About the Next Agent Stack
The reported MemPalace stack is almost aggressively unglamorous: local operation, SQLite, ChromaDB, no API key required, MIT license. None of that sounds magical. Good. Magic is usually where lock-in hides.
SQLite is tiny, boring, and battle-tested. ChromaDB handles vector retrieval, storing embeddings, which are numerical fingerprints of meaning, so the system can find related memories even when the wording changes. Put together, those choices suggest something important: an AI memory system does not need to be exotic to matter. It needs to be legible.
That legibility changes the buying criteria. If you are evaluating an agent or building one, inspect five things:
- Storage layer, Where do memories actually live: local files, SQLite, a vendor database, something exportable?
- Retrieval logic, What brings a memory back: keyword match, vector search, recency, hand-written rules, some mix?
- Provenance, Can you see where a remembered fact came from and when it entered the system?
- Deletion path, Can a user remove one memory cleanly, and does that deletion propagate everywhere it should?
- Portability, Can the memory survive a model swap, a product shutdown, or a move to another tool?
That checklist tells you more than a leaderboard does.
Here is the cleaner trade:
| Criteria | Cloud memory layer | Local/open-source memory layer |
|---|---|---|
| Inspectability | Usually partial or opaque | Directly auditable |
| Deletion | Often request-based, unclear propagation | User or developer can delete records directly |
| Portability | Tends to stay inside one product | Can move across tools and models |
| Latency | Depends on network and service design | Can be faster for on-device or nearby retrieval |
| Vendor lock-in | High by default | Lower, because storage format and logic are visible |
This is where the story turns. Model quality still matters, of course. But models are getting easier to swap than product teams expected. What users keep paying for may be the thing that remembers their workflows without becoming creepy, broken, or trapped.
And that memory layer becomes even more valuable in a world worried about provenance drift and synthetic sludge. The longer-term anxieties behind AI model collapse are not just about training data. They are about whether anyone can still trace what is true, what is stale, and what came from where. Local, inspectable memory is one small but concrete answer.
The Benchmark Claim Is the Story’s Weakest Part
Here is where the story gets strange.
The loudest MemPalace coverage leans on benchmark performance, especially the early “perfect score” framing. But the project’s own site acknowledges that the 100% hybrid score has been questioned and points readers toward a more credible 96.6% raw score. That does not make the project fake. It just means the benchmark story is the least sturdy part of the package.
The sharper problem is not merely that benchmarks are limited. It is that memory benchmarks overweight recall and underweight social failure modes.
A benchmark asks: did the system retrieve the right note from a test set? Real life asks uglier questions:
- Did it retrieve the right note in the wrong setting?
- Did it surface an outdated instruction that should have expired?
- Did it remember something the user thought they deleted?
- Did it pull in a poisoned memory with no provenance trail?
- Did it make the assistant feel observant, or invasive?
Those are not edge cases. Those are the product.
So yes, a 96.6% recall score can still produce something users distrust. An assistant that remembers accurately but unreliably, wrong scope, wrong time, wrong source, is like a very smart coworker who keeps opening the wrong drawer in your desk. Technically impressive. Socially exhausting.
That is why the benchmark claim matters less than the architecture claim. An open-source AI memory system running locally with ordinary components is technically plausible and strategically important. A disputed benchmark win is marketing. A portable, inspectable memory layer is infrastructure.

Once you draw it that way, the leaderboard starts to look tiny.
The ownership question is the whole question
Most celebrity-tech stories evaporate on contact. This one is more useful than most because it points at a hidden layer people usually ignore.
If you are choosing a tool, ask five plain questions:
- What does it remember?
- Where does that memory live?
- Can I inspect it?
- Can I delete or export it?
- Will it still be mine if I switch models or products?
If those answers are fuzzy, the product is borrowing trust it has not earned.
That is the real implication of MemPalace. The next battleground in agent memory is not just smarter recall. It is ownership, portability, and trust. The winning assistants may not be the ones that sound most intelligent in a demo. They may be the ones that remember like a good notebook: editable, reusable, and sitting in your bag instead of someone else’s server.
Key Takeaways
- In agent products, memory architecture, not model IQ, is becoming the real moat.
- A local, inspectable AI memory system changes user power because it affects portability, deletion, and trust.
- Real-world LLM memory fails through wrong-scope retrieval, stale memories, and poisoned memories, not just “forgetfulness.”
- MemPalace’s benchmark headlines deserve caution because recall scores can hide the social failure modes that make products feel unreliable.
- When evaluating open-source AI memory tools, inspect storage, retrieval logic, provenance, deletion, and portability.
Further Reading
- MemPalace official site, Primary project page with creator attribution, license details, and its own caveat about the questioned benchmark score.
- AIBase coverage of MemPalace, Secondary report summarizing the launch, local architecture claims, and benchmark assertions.
- Mezha.ua on MemPalace, Report describing the project as a free open-source memory system inspired by the memory palace method.
- Back2Gaming on MemPalace, Repost-style coverage built around a social claim and the “perfect score” framing.
- GitHub, Starting point for finding the repository linked from the official site and checking whether the implementation matches the pitch.
The next time an assistant remembers something important, do not ask only which model powered it. Ask whether the memory belongs to the product, or to you.