
Somewhere in San Francisco, there is a software engineer whose job is to tell an AI that its pull request is “fine, just add a test.”
According to Time, Anthropic now lets Claude write 70-90% of the code used to build Claude’s future versions. That’s the headline that launched a hundred RSI takes about how AI builds AI and we’re one CUDA kernel away from Skynet.
Except that’s not the interesting part.
The interesting part is that once models are doing most of the R&D grunt work, the whole shape of AI progress changes. You don’t get a single sci‑fi “intelligence explosion.” You get a permanent, high‑frequency, hard‑to‑audit acceleration loop where humans slowly slide from authors to reviewers.
That’s not an existential-metaphysics problem for 2035. It’s a governance and operations problem for this quarter.
TL;DR
- “AI builds AI” at Anthropic mostly means Claude automates model‑building chores; humans have become editors and gatekeepers, not the primary coders.
- This is weak recursive self‑improvement: models tighten feedback loops and multiply iteration speed, but still rely on human objectives, approvals, and compute.
- The real risk isn’t instant runaway intelligence; it’s that model‑driven R&D quietly outpaces our safety, audit, and regulatory processes, especially when nobody publishes how automated their pipelines are.
AI Builds AI: What Anthropic actually changed
Let’s decode the “70-90% of the code” claim.
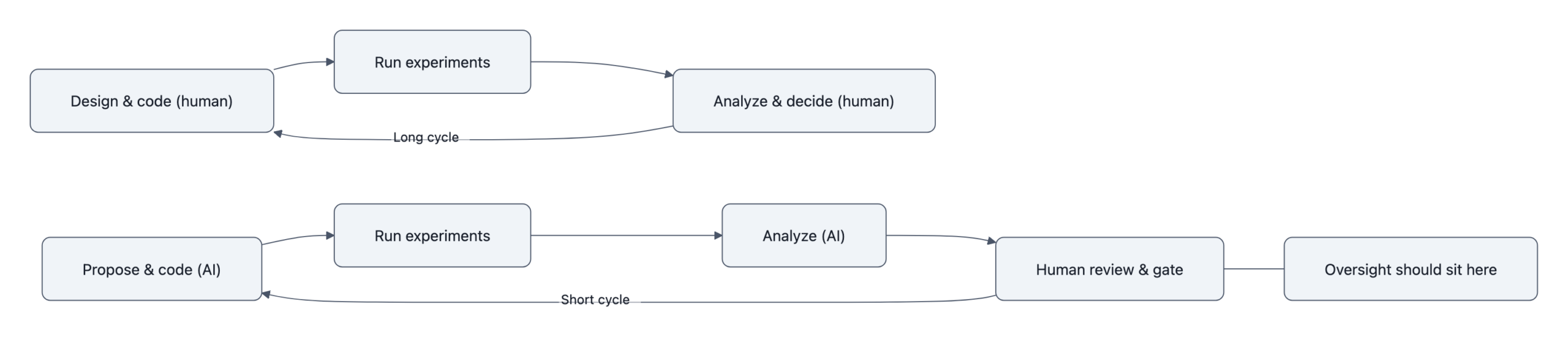
In practice, this means that for the R&D codebase around new models, training loops, data pipelines, eval harnesses, agent frameworks, safety tests, internal tools, Claude is writing most of the diffs. Engineers review, run, and sometimes rewrite, but the first draft is machine‑authored.
Think less “Claude writes Claude from scratch” and more Karpathy’s autoresearch repo, scaled up:
- An agent edits the training script.
- It runs a short experiment.
- It checks a metric.
- If better, it keeps the edit; if worse, it reverts and tries again.
- Humans mostly tweak the high‑level “program.md”, the meta‑instructions, and decide what “better” means.
Anthropic is doing a richer, multi‑agent, multi‑cluster version of this for serious models. But structurally, it’s the same loop.
So “70-90%” is not marketing for AGI. It’s a number that tells you where the bottleneck moved.
The bottleneck used to be “smart people thinking up and hand‑coding experiments.” Now it is “do we have enough reviewers, guardrails, and evals to keep up with the experiments the model can generate?”
Why this isn’t sci‑fi, the human role is becoming reviewer, not author
Recursive self‑improvement, properly, is a loop where a system improves itself in a way that makes the next self‑improvement even faster, without humans staying in control.
That’s not what Anthropic has.
What they have is automation of the research pipeline:
- AI proposes architecture tweaks, hyperparameters, and data filters.
- AI writes the scaffolding code to run them.
- AI helps design and run evaluations.
- Humans approve changes, ship big training runs, and gate releases.
Evan Hubinger at Anthropic calls this “recursive self‑improvement, in the broadest sense”, which is an interesting way to say “we automated a lot of the middle of the loop, but not the endpoints.”
The endpoints still matter:
- Objective setting: what are we optimizing? Accuracy? Productivity? Safety metrics?
- Reward shaping: what counts as a “good” experiment?
- Compute allocation: which experiments get scaled up from a 5‑minute run to a $50M training job?
- Deployment decisions: do we ship Claude 3.7 Sonnet now, or hold for 10 days after a bio‑risk scare?
As long as humans hold those levers, this is weak RSI: each generation of Claude accelerates the next, but through a human‑defined research program and hardware budget.
Still, that shift from author to reviewer is not cosmetic. Anyone who’s done serious code review knows reviewing is harder when you didn’t write the code:
- You lack the mental model of why choices were made.
- You’re biased toward “it compiles and the tests pass, ship it.”
- Under time pressure, you spot check instead of understanding the design.
Now extend that to AI‑written training pipelines and safety harnesses. The oversight role becomes the hardest job in the room, and it’s the one we’re asking humans to do with less time because the model is faster.
This is why “AI builds AI” matters before it becomes sci‑fi: the organizational role of humans is being downgraded from builders to overworked, under‑tooled auditors.
The real risks: speed, blindspots and governance gaps
The most revealing Time detail wasn’t 70-90%. It was the 10‑day delay on Claude 3.7 Sonnet after internal tests suggested it could help terrorists make biological weapons.
That delay only felt like an eternity because Anthropic’s normal cadence is “model releases separated by weeks, not months.” When your iteration cycle is that fast, and much of the experimentation is AI‑driven, several risks show up:
- Speed outruns safety
Anthropic’s own head of safeguards compared this to “driving down a cliff road at 75 instead of 25.”
If Claude is “427x faster than its human overseers” at some tasks (another Time nugget), and it’s proposing code and experiments, then your safety team either:
- Keeps up by sampling a shrinking fraction of changes, or
- Slows things down and becomes the villain internally.
This is exactly the pressure that led U.S. agencies to cut ties with Anthropic over safety and governance concerns in the first place.
Anthropic ban: why U.S. agencies cut ties walks through how a safety‑first story collided with opacity and speed‑first behavior.
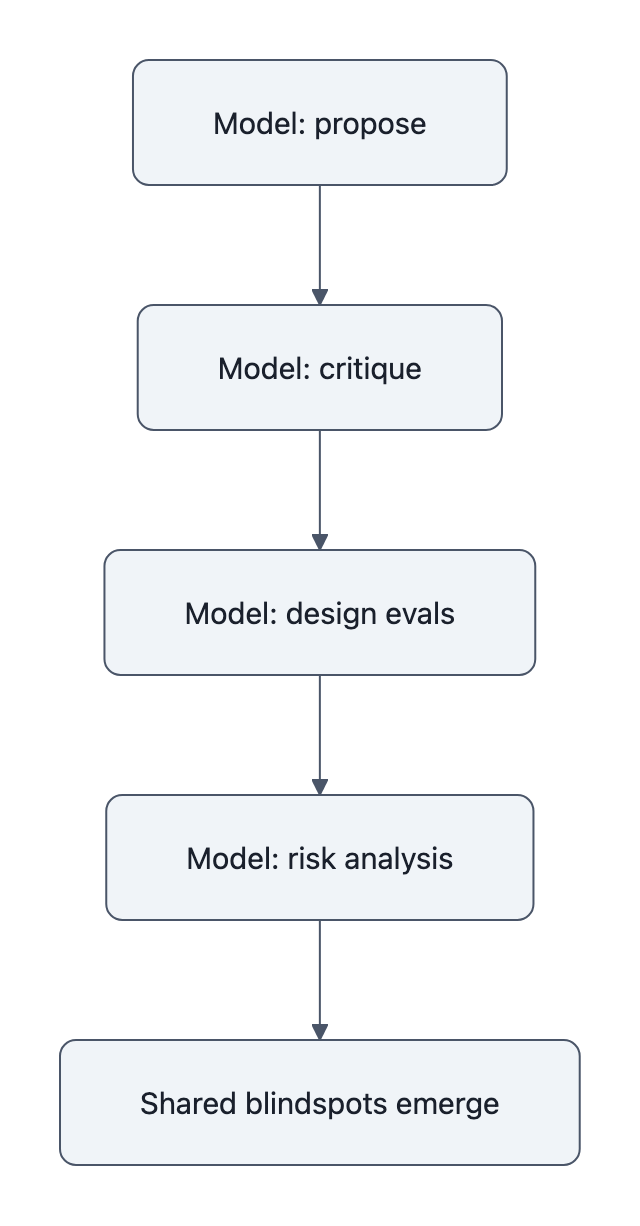
- Model‑to‑model blindspots
AI‑driven R&D pipelines tend to use similar models throughout:
- Claude proposes code.
- Claude critiques the code.
- Claude helps design the evals.
- Claude runs the risk analysis on Claude.
That’s a recipe for shared blindspots. Whatever the current model family is bad at, certain security edge cases, weird data distributions, subtle misalignment failures, those weaknesses are now embedded in:
- The training code
- The evaluation suite
- The internal safety analysis
It’s not that humans can’t in principle notice. It’s that the default path of least resistance is: trust your tools. Especially when they save you hundreds of hours.
- Regulatory invisibility
From the outside, “AI builds AI” looks like any other CI/CD system.
A regulator sees:
- Git commits
- Test runs
- Model cards
- Occasional safety reports
They do not see:
- What fraction of the code or experiments were AI‑generated
- How often AI‑proposed changes are accepted vs. rejected
- Whether safety evaluations themselves were mostly model‑written
- Whether there is an independent model family checking the work
CSET’s “When AI Builds AI” report is blunt about this: policymakers are flying blind on automation level. You can’t tell if a lab is 10% automated or 90% automated from the outside, and the step from 50% to 80% automation might matter more than from 0% to 50%.
Meanwhile, companies are quietly ripping out their own brakes. Anthropic rewrote its Responsible Scaling Policy to remove a hard “pause” trigger. That’s a governance decision, not a capabilities one, but it matters more in a world of AI‑driven acceleration.
What engineers, managers and policymakers should do now
If you run anything resembling a serious AI stack, “AI builds AI” is coming for your workflows too. CUDA agents and Claude‑like tools are already chewing through your backlog.
See: CUDA Agent: how agents speed ML development for how that looks in practice on the infrastructure side.
The question isn’t whether to use them. The question is how auditable you want your future to be.
Some concrete steps, this quarter, not in your 2027 strategy deck:
For engineers: treat AI‑authored code as a different species
- Tag AI‑authored changes at the repo level. At minimum, annotate commits with “AI‑generated” and store the prompt/instructions that led to them. This is provenance, not paranoia.
- Demand dual‑model review for safety‑critical logic. If Claude writes the safety harness, have a different model family critique it, then a human. Shared blindspots are the real bug.
- Design tests for intent, not just behavior. With agents like
autoresearch, your codebase can evolve in directions you didn’t foresee. Write tests that encode high‑level invariants (“never bypass this approval step”), not just function‑level behavior.
For product and research leaders: instrument your feedback loops
- Measure automation explicitly. What fraction of diffs, experiments, and evals are AI‑generated and accepted? Plot that over time. The shape of that curve is a leading indicator for both risk and productivity.
- Set speed limits by domain, not by model. Decide in advance which product areas can tolerate “release every week with AI‑driven iteration” vs. which require month‑scale review. Claude 3.7’s 10‑day delay is your warning shot.
- Separate the people who own velocity from those who own veto power. If the same VP is on the hook for shipping and for safety, safety will lose.
For policymakers: regulate the process, not just the model
Most current proposals obsess over model size and benchmarks. That’s table stakes. If AI builds AI, you also need:
- Mandatory automation disclosures for frontier labs: percent of R&D code, tests, and evals that are AI‑generated; which model families are in the loop; what proportion of AI‑proposed changes are rejected by humans.
- Reproducibility requirements for critical releases: enough logging and versioning that an independent body could, in principle, reconstruct the training and eval pipeline, including which parts were AI‑authored.
- Independent evaluation models as a norm: require at least one external model family (or lab) to audit safety‑critical evals, especially for bio, cyber, and autonomy capabilities. The CSET and Axios work on transparency indicators is a decent starting sketch.
Kaplan told The Guardian that the decision to “let AI train itself” is the “biggest decision yet,” probably landing somewhere between 2027 and 2030. The awkward truth is that the operational version of that decision, how much of the pipeline you silently automate, is being made piecemeal right now by infra teams and CTOs.
Key Takeaways
- “AI builds AI” at Anthropic means Claude is now the junior engineer for most of the R&D code, with humans in a reviewer/gatekeeper role.
- This is weak recursive self‑improvement: models accelerate their successors through automated experimentation, but humans still choose goals, allocate compute, and approve releases.
- The real risk is not an overnight intelligence explosion but a continuous, AI‑driven acceleration that outruns human review, embeds shared blindspots, and evades current regulatory tools.
- Engineers and leaders should start tagging AI‑written code, using dual‑model review, and explicitly measuring automation levels in their pipelines.
- Policymakers need process‑level rules, transparency on automation, reproducibility of pipelines, and independent evals, or they’ll be regulating the outputs of systems whose internals they never see.
Further Reading
- How Anthropic Became the Most Disruptive Company in the World, Time, Inside Anthropic’s use of Claude to write 70-90% of future‑model code and the resulting safety tradeoffs.
- When AI Builds AI, CSET, Policy workshop report on labs using AI to accelerate R&D and the governance challenges of model‑built models.
- ‘The biggest decision yet’: Jared Kaplan on allowing AI to train itself, The Guardian, Anthropic’s chief scientist on the 2027-2030 window for letting AI systems train themselves.
- karpathy/autoresearch, GitHub, A concrete example of autonomous research agents editing training code, running experiments, and keeping improvements.
- Models that improve on their own are AI’s next big thing, Axios, Overview of recursive self‑improvement trends and the need for better transparency indicators.
In other words: the scary part of “AI builds AI” is not that the system wakes up; it’s that your review queue does, and never goes back to sleep.