
The standard story is that LLMs work in words. They predict the next token, so surely their internal reasoning is mostly linguistic too. Language-agnostic representations are the strongest evidence yet that this story is incomplete.
I started this piece expecting a mild result: multilingual models probably compress similar translations into nearby vectors because they have to. The data says something stronger. Across multiple papers and independent experiments, semantically equivalent inputs tend to converge in the middle layers even when the surface form changes from English to Hindi, from prose to Python, or from text to equations.
That does not prove models “think” like humans. It does suggest a better mental model: language is the I/O; the middle of the model is closer to a shared semantic workspace.
If you haven’t been following this line of work, here’s the plain-English version. A transformer processes text layer by layer. Early layers stay closer to the input form, middle layers often capture higher-level features, and later layers prepare the output. The current question is whether those middle layers contain concept representations that are partly separate from any one language. The answer now looks like yes, probably, with some important caveats.
How LLMs Encode Concepts Across Languages

The clearest confirmed result is simple: in intermediate layers, meaning clusters more strongly than language.
That claim is plausible but well-supported, not settled law. In The Semantic Hub Hypothesis, researchers report that semantically equivalent inputs in different languages become similar in intermediate layers, and that this pattern extends beyond language to arithmetic, code, and even visual or audio inputs. Their core claim is not just “embeddings are close.” It is that the model appears to use a shared semantic space during processing.
David Noel Ng’s practitioner analysis found the same pattern across five models, Qwen3.5-27B, MiniMax M2.5, GLM-4.7, GPT-OSS-120B, and Gemma-4 31B, using eight languages: English, Chinese, Arabic, Russian, Japanese, Korean, Hindi, and French. In his tests, a sentence about photosynthesis in Hindi was closer, in middle-layer representation space, to photosynthesis in Japanese than to cooking in Hindi. That’s a useful “wait, really?” moment. If models were mostly organizing internal states by surface language, you’d expect same-language sentences to stay closer.
According to Ng, the pattern also survives a nastier test: code and equations. Expressions like 0.5 * m * v ** 2, the equation ½mv², and a natural-language description of kinetic energy converged toward similar internal regions. That result is one researcher’s analysis, not an independently benchmarked consensus, but it lines up with the semantic hub paper’s broader claim.
This is why “universal internal language” is the wrong phrase. A language would imply some stable symbolic syntax. The evidence points instead to cross-lingual representations in a latent geometric space, more like shared coordinates for concepts than hidden English.
What the New Evidence Actually Shows

Similarity alone is suggestive. Activation patching is the stronger test.
Activation patching means you take internal activations from one run of a model and splice them into another run at a chosen layer, then watch what changes. If two prompts differ in both language and meaning, patching can show which layers carry which kind of information.
In Separating Tongue from Thought, researchers used a translation task and found that output language is encoded earlier than the concept to be translated. That is a specific mechanistic claim, and here it is confirmed by the paper’s intervention results. They could change the concept without changing the language, and change the language without changing the concept, using patching alone.
That’s more than “these vectors look similar.” It means the model’s behavior can be causally manipulated by intervening on internal states that appear to separate concept from language.
The paper reports another result that is easy to miss and harder to explain away: patching in the mean representation of a concept across different languages did not hurt translation performance. It improved it. If the shared representation were just a messy averaging artifact, you’d expect degradation. Instead, the averaged concept latent was still useful.
There is still a reasonable objection from the Reddit discussion: maybe this is just what any bottlenecked system does. Fair. Compression pressure should push models toward shared latent factors. But activation patching weakens the “mere bottleneck” dismissal. A bottleneck story predicts compression. It does not automatically predict that swapping or averaging cross-language concept activations will preserve or improve downstream behavior in such a targeted way.
The right update is not “we discovered souls inside vectors.” It is narrower: multilingual LLM interpretability now has causal evidence that concept and language are at least partly separable inside transformer layers.
Why language-agnostic representations matter in practice
This sounds abstract until you look at what it explains.
First, it explains why multilingual prompting often works better than surface-level intuitions suggest. If the model maps different phrasings into a partially shared semantic workspace, then a translation can preserve more of the “reasoning state” than you’d expect from word-by-word substitution. That’s also why odd prompt workflows, draft in one language, refine in another, sometimes behave surprisingly consistently.
Second, it matters for interpretability. If you inspect only tokens, you may miss where the actual action is. The interesting thing may not be the sentence form but the internal concept being activated. That’s the backdrop for work on Gemma 4 Native Thinking: the question is less “what language is the model using?” than “what internal abstraction did it settle on?”
Third, it matters for reliability. If factual checking or correction operates at the level of shared concepts, then interventions there could generalize across paraphrases and languages better than token-level fixes. That connects to practical efforts to reduce LLM hallucinations. A model that stores a wrong concept in a shared latent form can be wrong in many languages at once. The upside is that a good correction might travel just as well.
Fourth, it matters for tool use and multimodal systems. If code, equations, and natural language partially meet in the same internal neighborhood, the model has a cleaner route to move between them. That helps explain why systems can jump from prose spec to code sketch to symbolic manipulation without acting like three unrelated tools taped together. The more ambitious agent story, see Karpathy Autoresearch, depends on this kind of abstraction layer working better than it has any obvious right to.
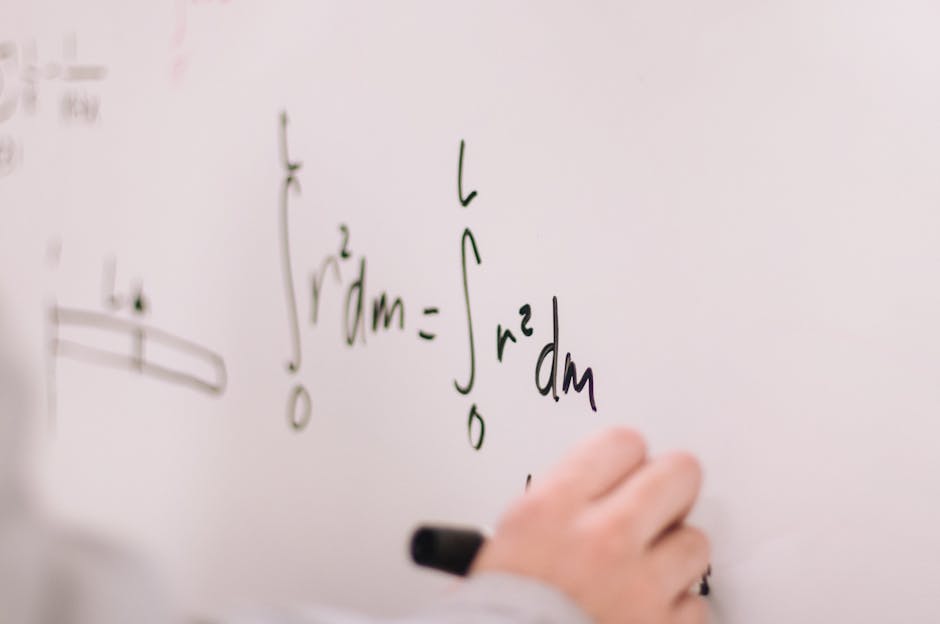
What Still Isn’t Proven Yet
This is where a lot of people overreach.
The evidence for language-agnostic representations is strong enough to change your mental model. It is not strong enough to justify “the model thinks in concepts exactly like humans do.” The papers show shared latent structure and causal separability in tested settings. They do not show conscious reasoning, human-like semantics, or a single universal internal code.
Some limits are obvious.
| Claim | Status | Why |
|---|---|---|
| Intermediate layers cluster by meaning across languages | Plausible, with repeated evidence | Reported in multiple experiments and models |
| Concept and language can be partly separated causally | Confirmed in tested setups | Activation patching changes one without fully changing the other |
| The same shared space spans code and equations | Plausible | Reported in papers and practitioner tests, but narrower and less standardized |
| LLMs think in a universal language | Unverified | Evidence points to latent geometry, not symbolic language |
| This disproves Sapir-Whorf for humans | False leap | The findings are about transformer internals, not people |
There is also a model-scope issue. Most of this evidence comes from multilingual transformers and translation-like tasks. As one commenter noted, a multilingual model may mask language-specific weaknesses by learning from many languages at once. A truly hard test would compare strongly monolingual models, or probe whether the shared semantic workspace stays stable in domains with weak parallel data.
And then there is the familiar interpretability problem: seeing a neat pattern in representation space is easier than proving the model relies on it broadly. Activation patching helps because it is causal. But even there, the interventions are local and task-specific. We have evidence of a shared workspace, not a full map of it.
Key Takeaways
- Language-agnostic representations are now supported by more than cosine-similarity charts; activation patching provides causal evidence.
- The best current model is language as I/O, concepts in the middle, not “the model reasons in English.”
- The evidence extends beyond translation to code and equations, which is the part that makes this more than a multilingual curiosity.
- This matters for prompting, interpretability, and hallucination work because token-level analysis can miss concept-level behavior.
- None of this proves human-style thought or a single universal internal language.
Further Reading
- The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities, The main paper arguing for a shared semantic hub across languages, code, arithmetic, and other modalities.
- Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers, The strongest causal evidence here, using activation patching to separate concept from language.
- LLM Neuroanatomy III: Do LLMs Break the Sapir-Whorf Hypothesis?, Independent practitioner analysis across five models and eight languages, with clear experimental intuition.
- llm-lang-agnostic, Reproducibility code for the activation-patching paper.
The old intuition was that models manipulate words and somehow meaning falls out. The newer evidence says the reverse is closer to true: words are the interface, and the interesting part happens underneath. The next interpretability wins will probably come from tracing concepts, not sentences.